When a thread first successfully locks a recursive mutex, it owns that mutex and the lock count is set to 1. Any other thread attempting to lock the mutex blocks until the mutex becomes unlocked. If the owner of the mutex attempts to lock the mutex again, the lock count is incremented, and the thread continues running.
When an owner unlocks a recursive mutex, the lock count is decremented. The mutex remains locked and owned until the count reaches zero. It is an error for any thread other than the owner to attempt to unlock the mutex.
A recursive mutex is useful when a thread requires exclusive access to a piece of data, but must call another routine (or itself) that also requires exclusive access to the data. A recursive mutex allows nested attempts to lock the mutex to succeed rather than deadlock.
This type of mutex is called "recursive" because it allows
you a capability not permitted by a normal (default) mutex. However,
its use requires more careful programming. For instance, if a
recursively locked mutex were used with a condition variable, the
unlock performed for a pthread_cond_wait() or
pthread_cond_timedwait() would not actually release the mutex.
In that case, no other thread can satisfy the condition of the
predicate, and the thread would wait indefinitely. See Section 2.4.2 for
information on the condition variable wait and timed wait routines.
2.4.1.4 Errorcheck Mutex
An errorcheck mutex is locked exactly once by a thread, like a normal mutex. If a thread tries to lock the mutex again without first unlocking it, the thread receives an error. If a thread other than the owner tries to unlock an errorcheck mutex, an error is returned. Thus, errorcheck mutexes are more informative than normal mutexes because normal mutexes deadlock in such a case, leaving you to determine why the thread no longer executes. Errorcheck mutexes are useful during development and debugging. Errorcheck mutexes can be replaced with normal mutexes when the code is put into production use, or left to provide the additional checking.
Errorcheck mutexes are slower than normal mutexes. They cannot be
locked without generating a call into DECthreads, and they do more
internal tracking.
2.4.1.5 Mutex Operations
To lock a mutex, use one of the following routines, depending on what you want to happen after the mutex is locked:
When a thread is finished accessing a piece of shared data, it unlocks the associated mutex by calling the pthread_mutex_unlock() routine. If other threads are waiting on the mutex, one is placed in the ready state. If more than one thread is waiting on the mutex, the scheduling policy (see Section 2.3.2.2) and the scheduling priority (see Section 2.3.2.3) determine which thread is readied, and the next running thread that requests it locks the mutex.
The mutex is not automatically granted to the first waiter. If the unlocking thread attempts to relock the mutex before the first waiter gets a chance to run, the unlocking thread will succeed in relocking the mutex, and the first waiter may be forced to reblock.
You can destroy a mutex---that is, reclaim its storage---by calling the pthread_mutex_destroy() routine. Use this routine only after the mutex is no longer needed by any thread. It is invalid to attempt to destroy a mutex while it is locked.
Warning
DECthreads does not currently detect deadlock conditions involving more than one mutex, but may in the future. Never write code that depends upon DECthreads not reporting a particular error condition.
A mutex attributes object allows you to specify values other than the defaults for mutex attributes when you initialize a mutex with the pthread_mutex_init() routine.
The mutex type attribute specifies whether a mutex is default, normal, recursive, or errorcheck. Use the pthread_mutexattr_settype() routine to set the mutex type attribute in an initialized mutex attributes object. Use the pthread_mutexattr_gettype() routine to obtain the mutex type from an initialized mutex attributes object.
The pthread_mutexattr_settype() and pthread_mutexattr_gettype() routines replace (and are equivalent to) the pthread_mutexattr_settype_np() and pthread_mutexattr_gettype_np() routines, respectively, that were available in previous DECthreads releases. The new routines provide a standardized interface; however, the older routines remain supported.
If you do not use a mutex attributes object to select a mutex type,
calling the pthread_mutex_init() routine initializes a normal
(default) mutex by default.
2.4.2 Condition Variables
A condition variable is a synchronization object used in conjunction with a mutex. It allows a thread to block its own execution until some shared data object reaches a particular state. A mutex controls access to shared data; a condition variable allows threads to wait for that data to enter a defined state.
The state is defined by a predicate in the form of a Boolean expression. A predicate may be a Boolean variable in the shared data or the predicate may be indirect; testing whether a counter has reached a certain value, or whether a queue is empty.
Each predicate should have its own unique condition variable. Sharing a single condition variable between more than one predicate can introduce inefficiency or errors unless you use extreme care.
Cooperating threads test the predicate and wait on the condition variable while the predicate is not in the desired state. For example, one thread in a program produces work-to-do packets and another thread consumes these packets (does the work). If there are no work-to-do packets when the consumer thread checks, that thread waits on a work-to-do condition variable. When the producer thread produces a packet, it signals the work-to-do condition variable.
You must associate a mutex with a condition variable.
A thread uses a condition variable as follows:
It is important to wait on the condition variable and evaluate the predicate in a while loop. This ensures that the program checks the predicate after it returns from the condition wait. This is due to the fact that, because threads execute asynchronously, another thread might consume the state before an awakened thread can run. Also, the test protects against spurious wake-ups and provides clearer program documentation.
For example, a thread A may need to wait for a thread B to finish a task X before thread A proceeds to execute a task Y. Thread B can tell thread A that it has finished task X by putting a TRUE or FALSE value in a shared variable (the predicate). When thread A is ready to execute task Y, it looks at the shared variable to see if thread B is finished (see Figure 2-5).
Figure 2-5 Thread A Waits on Condition Ready
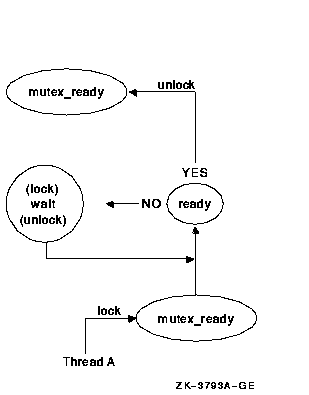
First, thread A locks the mutex named mutex_ready that is associated with the shared variable named ready. Then it reads the value in ready. This test is called the predicate. If the predicate indicates that thread B has finished task X, then thread A can unlock the mutex and proceed with task Y. If the predicate indicates that thread B has not yet finished task X, however, then thread A waits for the predicate to change by calling the pthread_cond_wait() routine. This automatically unlocks the mutex, allowing thread B to lock the mutex when it has finished task X. Thread B updates the shared data (predicate) to the state thread A is waiting for and signals the condition variable by calling the pthread_cond_signal() routine (see Figure 2-6).
Figure 2-6 Thread B Signals Condition Ready
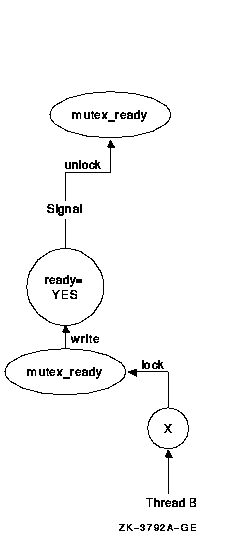
Thread B releases its lock on the shared variable's mutex. As a result of the signal, thread A wakes up, implicitly regaining its lock on the condition variable's mutex. It then verifies that the predicate is in the correct state, and proceeds to execute task Y (see Figure 2-7).
Figure 2-7 Thread A Wakes and Proceeds
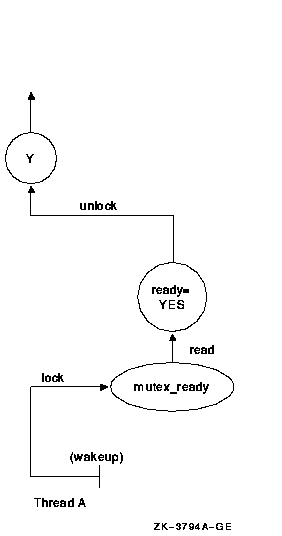
Note that although the condition variable is used for communication among threads, the communication is anonymous. Thread B does not necessarily know that thread A is waiting on the condition variable that thread B signals, and thread A does not know that it was thread B that awakened it from its wait on the condition variable.
Use the pthread_cond_init() routine to initialize a condition variable. To create condition variables as part of your program's one-time initialization code, see Section 3.7. You can also statically initialize condition variables using the PTHREAD_COND_INITIALIZER macro provided in the pthread.h header file.
Use the pthread_cond_wait() routine to cause a thread to wait until the condition is signaled or broadcasted. This routine specifies a condition variable and a mutex that you have locked. If you have not locked the mutex, the results of pthread_cond_wait() are unpredictable.
The pthread_cond_wait() routine automatically unlocks the mutex and causes the calling thread to wait on the condition variable until another thread calls one of the following routines:
If a thread signals or broadcasts on a condition variable and there are no threads waiting at that time, the signal or broadcast has no effect. The next thread to wait on that condition variable blocks until the next signal or broadcast. (Alternatively, the nonportable pthread_cond_signal_int_np() routine creates a pending wake condition, which causes the next wait on the condition variable to complete immediately.)
If you want to limit the time that a thread waits for a condition to be signaled or broadcasted, use the pthread_cond_timedwait() routine. This routine specifies the condition variable, mutex, and absolute time at which the wait should expire if the condition variable has not been signaled or broadcasted.
You can destroy a condition variable and reclaim its storage by calling
the pthread_cond_destroy() routine. Use this routine only
after the condition variable is no longer needed by any thread. A
condition variable cannot be destroyed while one or more threads are
waiting on it.
2.4.3 Condition Variable Attributes
Currently, no attributes affecting condition variables are defined. You cannot change any attributes in the condition variable attributes object.
The pthread_condattr_init() and
pthread_condattr_destroy() routines are provided for future
expandability of the DECthreads pthread interface and
to conform with the POSIX.1c standard. In this DECthreads release these
routines offer no useful function, because there are no DECthreads
routines available at this time for setting the attributes of condition
variable attributes objects.
2.5 Thread-Specific Data
Each thread can use an area of DECthreads-private memory where DECthreads stores thread-specific data objects. Use this memory to associate arbitrary data with a thread's context. Consider this as the ability to add user-specified fields to the current thread's context or as global variables that have private values in each thread.
A thread-specific data key is shared by all threads within the process---each thread has its own unique value for that shared key.
Use the following routines to create and access thread-specific data:
This chapter discusses programming disciplines that you should follow
as you use DECthreads routines in your programs. Pertinent examples
include programming for asynchronous execution, choosing a
synchronization mechanism, avoiding priority scheduling problems,
making code thread safe, and working with code that is not thread safe.
3.1 Designing Code for Asynchronous Execution
When programming with threads, always keep in mind that the execution of a thread is inherently asynchronous with respect to other threads running the system (or in the process).
In short, there is no guarantee of when a thread will start. It can start immediately or not for a significant period of time, depending on the priority of the thread in relation to other threads that are currently running. When a thread will start can also depend on the behavior of other processes, as well as on other threaded subsystems within the current process.
You cannot depend upon any synchronization between two threads unless you explicitly code that synchronization into your program using one of the following:
Some implementations of threads operate by context-switching threads in user mode, within a single operating system process. Context switches between such threads occur only at relatively determinate times, such as when you make a blocking call to the threads library or when a timeslice interrupt occurs. This type of threading library might be termed "slightly asynchronous," because such a library tolerates many classes of errors in your application.
Systems that support kernel threads are less "forgiving" because context switches between threads can occur more frequently and for less deterministic reasons. Systems that allow threads within a single process to run simultaneously on multiple processors are even less forgiving.
The following subsections present examples of programming errors.
3.1.1 Avoid Passing Stack Local Data
Avoid creating a thread with an argument that points to stack local data, or to global or static data that is serially reused for a sequence of threads.
Specifically, the thread started with a pointer to stack local data may
not start until the creating thread's routine has returned, and the
storage may have been changed by other calls. The thread started with a
pointer to global or static data may not start until the storage has
been reused to create another thread.
3.1.2 Initialize DECthreads Objects Before Thread Creation
Initialize DECthreads objects (such as mutexes) or global data that a thread uses before creating that thread.
On slightly asynchronous systems this is often safe, because the thread will probably not run until the creator blocks. Thus, the error can go undetected initially. On another system (or in a later release of the operating system) that supports kernel threading, the created thread may run immediately, before the data has been initialized. This can lead to failures that are difficult to detect. Note that a thread may run to completion, before the call that created it returns to the creator. The system load may affect the timing as well.
Before your program creates a thread, it should set up all requirements
that the new thread needs in order to execute. For example, if your
program must set the new thread's scheduling parameters, do so with
attributes objects when you create it, rather than trying to use
pthread_setschedparam() or other routines afterwards. To set
global data for the new thread or to create synchronization objects, do
so before you create the thread, else set them in a
pthread_once() initialization routine that is called from each
thread.
3.1.3 Don't Use Scheduling As Synchronization
Avoid using scheduling policy and scheduling priority attributes of threads as a synchronization mechanism.
In a uniprocessor system, only one thread can run at a time, and when a higher-priority (real-time policy) thread becomes runnable, it immediately preempts a lower-priority running thread. Therefore, a thread running at higher priority might erroneously be presumed not to need a mutex to access shared data.
On a multiprocessor system, higher- and lower-priority threads are likely to run at the same time. Situations can even arise where higher-priority threads are waiting to run while the threads that are running have a lower priority.
Regardless of whether your code will run only on a uniprocessor
implementation, never try to use scheduling as a synchronization
mechanism. Even on a uniprocessor system, your SCHED_FIFO thread can
become blocked on a mutex (perhaps in a called library routine), on an
I/O operation, or even a page fault. Any of these might allow a lower
priority thread to run.
3.2 Memory Synchronization Between Threads
Your multithreaded program must ensure that access to data shared between threads is synchronized.
The POSIX.1c standard requires that, when calling the following routines, a thread synchronizes its memory access with respect to other threads:
| fork() | pthread_cond_signal() |
| pthread_create() | pthread_cond_broadcast() |
| pthread_join() | sem_post() |
| pthread_mutex_lock() | sem_trywait() |
| pthread_mutex_trylock() | sem_wait() |
| pthread_mutex_unlock() | wait() |
| pthread_cond_wait() | waitpid() |
| pthread_cond_timedwait() |
If a call to one of these routines returns an error, synchronization is not guaranteed. For example, an unsuccessful call to pthread_mutex_trylock() does not necessarily provide actual synchronization.
Synchronization is a "protocol" among cooperating threads,
not a single operation. That is, unlocking a mutex does not guarantee
memory synchronization with all other threads---only with threads that
later perform some synchronization operation themselves, such as
locking a mutex.
3.3 Using Shared Memory
Most threads do not operate independently. They cooperate to accomplish a task, and cooperation requires communication. There are many ways that threads can communicate, and which method is most appropriate depends on the task.
Threads that cooperate only rarely (for example, a boss thread that only sends off a request for workers to do long tasks) may be satisfied with a relatively slow form of communication. Threads that must cooperate more closely (for example, a set of threads performing a parallelized matrix operation) need fast communication---maybe even to the extent of using machine-specific hardware operations.
Most mechanisms for thread communication involve the use of shared
memory, exploiting the fact that all threads within a process share
their full address space. Although all addresses are shared, there are
three kinds of memory that are characteristically used for
communication. The following sections describe the scope (or, the range
of locations in the program where code can access the memory) and
lifetime (or, the length of time the memory exists) of each of the
three types of memory.
3.3.1 Using Static Memory
Static memory is allocated by the language compiler when it translates source code, so the scope is controlled by the rules of the compiler. For example, in the C language, a variable declared as extern can be accessed anywhere, and a static variable can be referenced within the source module or routine, depending on where it is declared.
In this discussion, static memory is not the same as the C language static storage class. Rather, static memory refers to any variable that is permanently allocated at a particular address for the life of the program.
It is appropriate to use static memory in your multithreaded program when you know that only one instance of an object exists throughout the application. For example, if you want to keep a list of active contexts or a mutex to control some shared resource, you would not want individual threads to have their own copies of that data.
The scope of static memory depends on your programming language's
scoping rules. The lifetime of static memory is the life of the program.
3.3.2 Using Stack Memory
Stack memory is allocated by code generated by the language compiler at run time, generally when a routine is initially called. When the program returns from the routine, the storage ceases to be valid (although the addresses still exist and might be accessible).
Generally, the storage is valid while the routine runs, and the actual address can be calculated and passed to other threads; however, this depends on programming language rules. If you pass the address of stack memory to another thread, you must ensure that all other threads are finished processing that data before the routine returns; otherwise the stack will be cleared, and values might be altered by subsequent calls. The other threads will not be able to determine that this has happened, and erroneous behavior will result.
The scope of stack memory is the routine or a block within the routine.
The lifetime is no longer than the time during which the routine
executes.
3.3.3 Using Dynamic Memory
Dynamic memory is allocated by the program as a result of a call to some memory management routine (for example, the C language run-time routine malloc() or the OpenVMS common run-time routine LIB$GET_VM).
Dynamic memory is referenced through pointer variables. Although the pointer variables are scoped depending on their declaration, the dynamic memory itself has no intrinsic scope or lifetime. It can be accessed from any routine or thread that is given its address and will exist until explicitly made free. In a language supporting automatic garbage collection, it will exist until the run-time system detects that there are no references to it. (If your language supports garbage collection, be sure the garbage collector is thread safe.)
The scope of dynamic memory is anywhere a pointer containing the address can be referenced. The lifetime is from allocation to deallocation.
Typically dynamic memory is appropriate to manage persistent context.
For example, in a thread-reentrant routine that is called multiple
times to return a stream of information (such as to list all active
connections to a server or to return a list of users), using dynamic
memory allows the program to create multiple contexts that are
independent of all the program's threads. Thus, multiple threads could
share a given context, or a single thread could have more than one
context.
3.4 Managing a Thread's Stack
For each thread created by your program, DECthreads sets a default stack size that is acceptable to most applications. You can also set the stacksize attribute in a thread attributes object, to specify the stack size needed by the next thread created.