Sémantický web
Úvod
W3 Consorcium v roce 2001 zakládá skupinu Semantic Web Activity, která mimo jiné definuje sémantický web (semantic web) tak, že:
- informace na webu budou mít přesně daný význam,
- informacím na webu může porozumět a zpracovávat je počítač,
- počítače mohou integrovat a využívat informace z webu.
K tomuto účelu bylo nezbytné popisovat zdroje na webu, např.:
- popis informací o webové stránce (autor, datum vytvoření a změny, obsah, klíčová slova),
- popis vlastností zboží v eshopech (cena, dostupnost), událostí,
- popis obsahu a hodnocení,
- popis pro vyhledávací stroje,
- a další.
Tyto uvedené představy jso už dnes historie, přesto si tato myšlenka nalezla své místo v jiných oblastech:
- Svět propojených (otevřených) dat,
- Linked Data (LD) + Open Data,
- Linked Open Data (LOD).
- V některých obměnách otevřenost dat nevylučuje nutnost přístupu pouze autorizovaných osob k některým zdrojům.
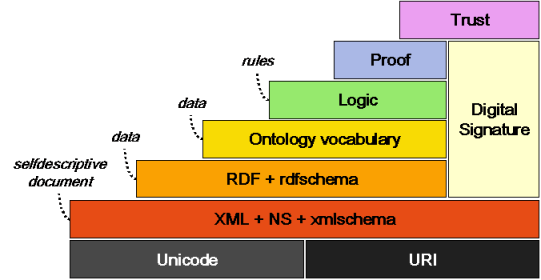
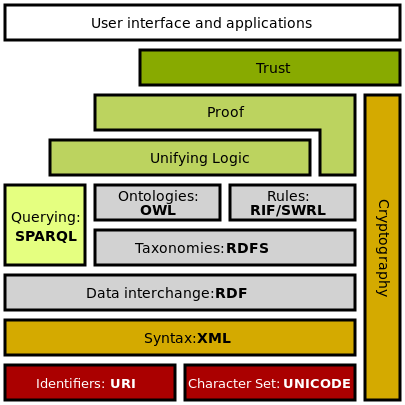
Vrstvy sémantického webu
- Unicode + Jednoznačné identifikátory (URI, IRI) – lokalizace a jméno
- XML + jmenné prostory + XML Schema
- RDF + RDF Schema
- Ontologie (OWL)
- Logika, usuzování, odvozování znalostí (tvrzení) – odvozovací pravidla (rules)
- Důkaz a dokazatelnost (proof)
- Důvěra (trust, digital signature, cryptography)
- Uživatelské rozhraní a aplikace
RDF
Zkratka RDF odkazuje na Resource Description Framework, což můžeme přeložit jako rámec popisu zdrojů.
Jeho autorem je W3 Consorcium a byl převážně navržen pro popis zdrojů na webu. RDF není jen rámec, ale také datový model či slovník.
RDF je navržen maximálně obecně, aby mohl být čten a pochopen strojem (počítačem, ale zobrazení informace témto jazykem nebylo
pochopitelné pro lidi.
Zápis RDF využívá pro zápis:
- XML, protože XML zjednodušuje výměnu informací mezi různými typy aplikací i operačních systémů. Tato syntaxe je označována jako RDF/XML.
- i jiné způsoby bez ztráty informace, např. notace N-TRIPLE, TURTLE, JSON a další.
RDF má tyto silné stránky:
- integrace dat a informací (URI),
- opakované použití dat a informací (jednotné identifikátory, slovníky),
- strukturované nebo částečně strukturovaná data,
- oddělení datového modelování a syntaxe reprezentačního jazyka,
- začlenění zdrojů na webu na základě metadat popisujících jejich obsah,
- možnost klasifikace,
- možnost inference dat,
- reprezentace třídy i její instance stejným způsobem.
Princip a popis RDF trojice
RDF je založeno na atomickém prvku označovaném trojice (triple). Trojice popisuje vlastnost zdroje. Trojice se skládá ze tří částí:
- zdroj (resource, subjekt) je cokoliv co chceme popisovat a má jednoznačný identifikátor,
- vlastnost (property, predikát) je zdrojem, který má název a je jednoznačně určen identifikátorem,
- hodnota (property value, objekt) je konkrétní hodnota (literál) nebo identifikátor jiného zdroje.
Trojice tvoří vždy jedno platné tvrzení. Máme-li více tvrzení zapisujeme je jako odpovídající počet trojic. Spojením trojic nám vzniká
popis reálného světa v podobě orientovaného grafu:
- zdroje jsou uzly
- vlastnosti jsou hrany
Vše jsou trojice (triples) resp. čtveřice (quads). Datové úložiště označujeme jako:
- RDF store (RDF úložiště),
- Triple-store (úložiště tripletů),
- Graph database (grafová databáze), Quad-store (triplet uložen v rámci grafu).
Ilustrace převodu tvrzení do RDF
Příklad tvrzení: Rozvrhovou akci v pondělí 9.20 vede Petr. lze zapsat do trojice:
- zdroj = Rozvrhová akce v pondělí 9.20,
- vlastnost = vede,
- objekt = Petr.
Vidíme, že tam jsou i další tvrzení, které se vztahují k rozvrhové akci a blíže ji specifikují. Jak budou vypadat další tvrzení?
Další tvrzení přepsaná RDF trojicemi:
<zdroj> <vlastnost> <objekt> .
=======================================================
<Rozvrhová akce v pondělí 9.20> <vede> <Petr> .
<Rozvrhová akce v pondělí 9.20> <den> <pondělí> .
<Rozvrhová akce v pondělí 9.20> <zacina> <9.20> .
<9.20> <hodin> <9> .
<9.20> <minut> <20> .
...
Výše uvedený zápis (bez prvních dvou řádek) se označuje N-TRIPLE notace a každá trojice je vždy na samostatném řádku ukončená znakem tečky.
Zdroje jsou uzavřeny ve špičatých závorkách a text je v uvozovkách.
Identifikátory
Výše uvedený zápis tvrzení byl ilustrační a v této podobě by neměl odpovídající přínos/význam. Zdroje musí být jednoznačně identifikovatelné buď jako
URI (Uniform Resource Identifier) nebo jako IRI (Internationalized Resource Identifier). URI nebo IRI má tento obecný tvar:
scheme:[//[user:password@]host[:port]][/]path[?query][#fragment]
IRI umožňuje oproti URI v řetězci použít Unicode znaky splňující pravidla dle RFC 3987.
URI nebo IRI nabízí známé specializace:
-
URN (Uniform Resource Name) – jméno zajistí identifikaci, ale nikoliv lokalizaci
-
URL (Uniform Resource Locator) – identifikuje přístupovou metodu i místo v síti
Z důvodu možnosti propojení dat (v budoucnosti) na webu je doporučeno použití schéma/protokolu HTTP(S).
V našem příkladě použijeme např. jmenný prostor http://zcu.cz/rdf/ a zdroje i vlastnosti jím identifikujeme:
<zdroj> <vlastnost> <objekt> .
=========================================================================
<http://zcu.cz/rdf/1> <http://zcu.cz/rdf/vede> "Petr" .
<http://zcu.cz/rdf/1> <http://zcu.cz/rdf/den> "pondělí" .
<http://zcu.cz/rdf/1> <http://zcu.cz/rdf/zacina> <http://zcu.cz/rdf/2> .
<http://zcu.cz/rdf/2> <http://zcu.cz/rdf/hodin> "9" .
<http://zcu.cz/rdf/2> <http://zcu.cz/rdf/minut> "20" .
...
Datový typ a jazyk hodnoty
Pro hodnoty lze definovat datový typ nebo jazyk. V notacích N-TRIPLE a Turtle:
Slovníky a jmenné prostory
Ilustrační příklad ukazuje popis několika tvrzení, ale rozumíme mu (pravděpodobně) pouze my. Pro zajištění shody a pochopení ostatními lidmi
i stroji je popis (zatím) nevhodný, resp. nedostatečný. Vlastnosti, které jsme si zavedli jsou naše a lokální. Kdokoliv jiný se na ně podívá,
nemusí pochopit jejich správný význam nebo je správně interpretovat:
zcu:den – den v měsíci? den v roce?zcu:hodin – aktuální čas? čas události? 12/24 hod. – dopoledne nebo odpoledne?zcu:minut – počet minut od/k čeho/čemu?zcu:vede – vede projekt?zcu:zacina – co/kde/proč začíná?
Takto uvedené vlastnosti jsou „vytrženy z kontextu“, chybí nám kontext nebo spíše význam – sémantika vlastností.
Zjednodušeně řečeno, proto vznikají slovníky nebo ontologie, které definují a současně dokumentují potřebný kontext,
vztahy, doménu, obor hodnot, ...
Vytvoříme-li si odpovídající slovník (resp. ontologii) a zveřejníme jej – data a informace může využít už i někdo další a mohou se sdílet na webu.
Problém?! Když si úplně každý vytvoří svůj vlastní slovník, pak bude výsledek nepoužitelný, protože data budou sdílená, ale možnosti
využití a interpretace ostatními budou minimální.
Řešením tohoto problému jsou existující základní RDF slovníky a ontologie, které přináší rámec jak nad RDF popisovat zdroje jednotným způsobem:
-
RDF slovník přináší základní prvky;
prefix: rdf,
jmenný prostor: http://www.w3.org/1999/02/22-rdf-syntax-ns#
- třídy,
- vlastnosti,
- hodnoty,
rdf:type – určení, že je popisovaný zdroj nějakého typu/třídy.
-
RDF Schema (RDFS) rozšíření základního RDF slovníku;
prefix: rdfs,
jmenný prostor: http://www.w3.org/2000/01/rdf-schema#
- umožňuje popsat pro aplikace specifické třídy a vlastnosti
-
podobnost s objektově orientovaným programováním (OOP)
- lze vytvářet hierarchii tříd (sub-class) a vlastností (sub-property)
- zdroje mohou být definovány jako instance tříd
- popisuje strukturu dat
-
Web Ontology Language (OWL)
-
Web Ontology Language 2 (OWL2) rodina jazyků pro reprezentaci znalostí při tvorbě ontologií.
- popisuje sémantické vztahy
-
owl:sameAs – pro popis, že nějaké dvě „věci“ jsou totéž
- užitečné při spojování více schémat nebo zdrojů dat –> Linked Data
Závěr: RDF definuje jak psát popis a OWL definuje co psát.
Používané notace RDF dat
Pro účely přehlednějšího a stručnějšího (úspornějšího) zápisu se používají prefixy i další notace. Pro stejný příklad popisu
pondělní rozvrhové akce použijeme další zápisy.
Notace Turtle
Přímo výše uvedený příklad zapíšeme v notaci Turtle:
<http://zcu.cz/rdf/1>
http://zcu.cz/rdf/:vede "Petr" ;
http://zcu.cz/rdf/:den "pondělí" ;
http://zcu.cz/rdf/:zacina http://zcu.cz/rdf/2 .
<http://zcu.cz/rdf/2>
http://zcu.cz/rdf/:hodin "9" ;
http://zcu.cz/rdf/:minut "20" .
Tvrzení patřící stejnému subjektu oddělujeme středníkem,
více hodnot u stejné vlastnosti oddělujeme čárkou a za posledním tvrzením je tečka.
Ke zvolenému jmennému prostoru nadefinujeme prefix zcu a data ve výše uvedené notaci Turtle budou:
@prefix zcu: <http://zcu.cz/rdf/> .
<http://zcu.cz/rdf/1>
zcu:vede "Petr" ;
zcu:den "pondělí" ;
zcu:zacina zcu:2 .
<http://zcu.cz/rdf/2>
zcu:hodin "9" ;
zcu:minut "20" .
Ve formátu Turtle může být na začátku deklarace prefixů začínající znakem zavináče a slovem prefix,
za nímž následuje vlastní prefix a za dvojtečkou úplné URI/IRI jmenného prostoru za kterým je tečka.
Notace RDF/XML
Stejný zápis v provedení notace RDF/XML:
<rdf:RDF xmlns:zcu="http://zcu.cz/rdf/">
<rdf:Description rdf:about="http://zcu.cz/rdf/1">
<zcu:vede>Petr</zcu:vede>
<zcu:den>pondělí</zcu:den>
<zcu:zacina>
<rdf:Description rdf:about="http://zcu.cz/rdf/2">
<zcu:hodin>9</zcu:hodin>
<zcu:minut>20</zcu:minut>
</rdf:Description>
</zcu:zacina>
</rdf:Description>
</rdf:RDF>
Používá se jmenný prostor rdf, který je rezervovaný. Prefixy jsou definovány v kořenovém elementu rdf:RDF.
Příklad v základní RDF/XML notaci včetně použitého RDF jmenného prostoru:
<?xml version="1.0"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:zcu="http://zcu.cz/rdf/">
<rdf:Description rdf:about="http://zcu.cz/rdf/1">
<zcu:vede>Petr</zcu:vede>
<zcu:den>pondělí</zcu:den>
<zcu:zacina rdf:resource="http://zcu.cz/rdf/2" />
</rdf:Description>
<rdf:Description rdf:about="http://zcu.cz/rdf/2">
<zcu:hodin>9</zcu:hodin>
<zcu:minut>20</zcu:minut>
</rdf:Description>
</rdf:RDF>
Uvedené serializace RDF dat jsou vzájemně převoditelné – bezztrátově.
- Obvykle záleží na aplikaci, v jaké notaci data vyžaduje.
- Lze serializovat také do formátu JSON.
Přidání tvrzení
Nová tvrzení/trojice stačí k původním jen přidat.
<zdroj> <vlastnost> <objekt> .
===========================================================
<Petr> <je> <Jméno> .
<Petr> <je> <Osoba> .
<Petr> <je> <Muž> .
<pondělí> <je> <Den v týdnu> .
...
Tyto trojice mohou pocházet např. z jiného zdroje, slovníku nebo ontologie.
Lze se dotazovat u více zdrojů současně, a to prostřednictvím distribuované prostředí webu – SPARQL Endpoint.
Pokud zdroj používá jiné identifikátory, slovníky nebo ontologie, lze je propojit (merge) přidáním tvrzení s vlastnostmi
owl:sameAs, owl:differentFrom a owl:AllDifferent.
Porovnání OOP s RDF
Kocept RDF a OWL je velmi obecný, avšak lze najít podobnost s OOP přístupem.
-
Dědičnost:
- tříd,
- vlastností,
- vícenásobná.
-
Porovnání:
- RDF zdroj = objekt v OOP,
- Vlastnost = instanční proměnná v OOP.
-
Instance (objekt/data) je typu (
rdf:type) nějaké třídy nebo tříd.
Porovnání s relační databází
Zásadní rozdíl je ve způsobu přístupu k datům.
- Schéma relační databáze nebude (neměl by :-) ) nikdo cizí číst a zkoumat, k datům mají přístup pouze vybrané aplikace/uživatelé.
- V RDF je veřejné schéma dat (slovník nebo ontologie).
- Účelem RDF je zpřístupnit data a informace včetně jejich významu na webu ve vhodné strojově čitelné podobě.
- V případě Linked Data jsou navíc publikovány také vztahy (relace) mezi informacemi.
Schéma databáze = datový model je pevně definován
- V RDF je schéma prostřednictvím slovníků a ontologií (RDF, OWL).
- V RDF neexistuje pevné schéma, může se měnit.
- V jednom RDF úložišti lze mít data s různým schématem současně.
Tabulka = entita
Sloupec tabulky = atribut entity
- V RDF se jedná o vlastnost (property)
- V RDF nemusí vlastnost náležet ke konkrétní třídě (chybí rdfs:domain).
- RDF vlastnost definuje jednu nebo více domén (rdfs:domain)
-
Existence
rdfs:domain u RDF vlastnosti navíc znamená:
- instance, kde je RDF vlastnost použita, bude typu (třídy), který
rdfs:domain specifikuje.
Datový typ atributu = povolený datový typ hodnot
- V RDF není kontrola datového typu.
- Datový typ nemusí být určen.
-
V RDF vlastnost může definovat více datových typů (
rdfs:range).
- Hodnoty stejné vlastnosti mohou mít různé datové typy.
-
Existence
rdfs:range u RDF vlastnosti navíc znamená, že všechny hodnoty, kde byl použit predikát s rdfs:range,
bude datového typu, který definoval.
Záznam = řádek tabulky
- V RDF je to několik trojic najednou, protože jedna trojice by odpovídala hodnotě v jednom ze sloupců tabulky.
-
POZOR: Z neexistence tvrzení/odpovědi nelze v RDF nic vyvozovat!
-
když dotaz na X vrátí prázdný výsledek
- v relační databázi = X neexistuje,
-
v RDF = nevíme zda X existuje, jen nemusíme mít k dispozici data,
- Open World Assumption (OWA).
Vývoj a vývojové nástroje
RDF úložiště
- in-memory – dle použitého frameworku
-
perzistentní
Programovací jazyky
Seznam dalších nástrojů souvisejících s RDF: https://www.w3.org/RDF/
SPARQL – dotazovací jazyk
Historie jazyka
SPARQL 1.0 (2008)
- dotazovací jazyk
- využívá HTTP Protocol
- výsledky – ve formátech XML a JSON
SPARQL 1.1 (W3C Recommendation 21 March 2013)
- SPARQL 1.1 Overview – https://www.w3.org/TR/sparql11-overview/
- SPARQL 1.1 Query Language https://www.w3.org/TR/2013/REC-sparql11-query-20130321/
- Updated Query Language & HTTP Protocol
- SPARQL 1.1 Update
- Graph Store HTTP Protocol (RESTful přístup k RDF grafům)
- SPARQL 1.1 Service Descriptions – popis služeb poskytovaných SPARQL endpointy
- SPARQL 1.1 Entainments – odvozování a SPARQL
- SPARQL 1.1 Basic Federated Query – dotazování více SPARQL endpointů současně v rámci jednoho dotazu.
Popis jazyka
Jazyk umožňuje:
- získat data (
SELECT, DESCRIBE, CONSTRUCT)
- objevovat data dotazováním na neznámé vztahy (
ASK, DESCRIBE),
- transformovat RDF data z jednoho schéma do jiného (
CONSTRUCT).
-
provést komplexní dotazování přes více databází v jednom jednoduchém dotazu
- Federated SPARQL Query (SERVICE)
Výběrové typy dotazu:
ASKCONSTRUCTDESCRIBESELECT
Formát výsledku výběrových dotazů – závisí na typu dotazu:
ASK – vrací boolean (hodnotu true/false),CONSTRUCT a DESCRIBE – vrací RDF graf,SELECT – vrací tabulku – CSV/TSV, HTML, TXT, JSON, XML, … záleží na RDF úložišti/databázi, může poskytovat i např. XLS soubory.
Aktualizace grafu:
Správa grafu:
CREATE – vytvoření nového grafu (může-li existovat prázdný graf),DROP – odstranění grafu i jeho obsahu,COPY – kopíruje obsah grafu do jiného,MOVE – přesune obsah grafu do jiného,ADD – duplikuje obsah jednoho grafu do jiného.
Schéma dotazu
# deklarace prefixů
PREFIX foo: <http://example.com/resources/>
...
# definice datasetu/grafu/zdroje
FROM ...
# výsledek dotazu
SELECT ...
# podmínka — vzor dotazu (query pattern)
WHERE {
...
}
# modifikátory dotazu
ORDER BY ...
V části SELECT:
- se proměnné čárkou neoddělují,
- vrací tabulku hodnot proměnných, které splňují část podmínky
WHERE.
Proměnná začíná prefixem otazníku (dolaru): ?s ?p ?o.
- Může nabývat jakékoliv hodnoty: zdroje (IRI/URI ) i literálu.
V části WHERE:
Filtrování hodnot:
FILTER pracuje s podmínkami typu boolean.- logické:
!, &&, ||
- matematické:
+, -, *, /
- porovnání:
=, !=, <, >, IN, NOT IN, ...
- testy RDF/SPARQL:
isURI, isBlank, isLiteral, isNumeric, bound, !bound
-
SPARQL funkce:
str, lang, datatypesameTerm, langMatches, regex, REPLACE, ...- podmínky:
IF, COALESCE, EXISTS, NOT EXISTS
- konstruktory:
URI, BNODE, STRDT, STRLANG, UUID, STRUUID
- řetězce:
STRLEN, SUBSTR, UCASE, LCASE, STRSTARTS, STRENDS, CONTAINS, STRBEFORE, STRAFTER, CONCAT, ENCODE_FOR_URI
- matematika:
abs, round, ceil, floor, rand
- datum a čas:
now, year, month, day, hours, minutes, seconds, timezone, tz
- hash:
MD5, SHA1, SHA256, SHA384, SHA512
FILTER (?hodnota > 1000 && langMatches(lang(?nazev), "EN")) .
lang získá jazyk specifikovaný u textového řetězcelangMatches porovná s uvedeným jazykem nebo jejich výčtem
Ukázková data
# https://www.w3.org/TR/2013/REC-sparql11-query-20130321/#construct
@prefix foaf: <http://xmlns.com/foaf/0.1/> . # Friend-of-a-Friend
<abc> foaf:name "Alice" .
<abc> foaf:mbox <mailto:alice@example.org> .
Typy dotazů jsou:
SELECT všechny nebo podmnožinu proměnných z podmínkové části
# příklad 1 - všechny trojice
SELECT ?s ?p ?o
WHERE {
?s ?p ?o .
}
# příklad 1 - všechny vlastnosti a jejich hodnoty
SELECT ?p ?o
WHERE {
<abc> ?p ?o .
}
CONSTRUCT vrací RDF graf sestavený dle šablony trojic
- získání pod-grafu
- vytvoření odvozených dat
- transformace dat mezi schématy nebo vytváření nových tvrzení
# https://www.w3.org/TR/2013/REC-sparql11-query-20130321/#construct
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
PREFIX vcard: <http://www.w3.org/2001/vcard-rdf/3.0#>
# příklad 1 - jen filtrování
CONSTRUCT WHERE { ?x foaf:name ?name . }
# příklad 2 - transformace schéma
CONSTRUCT {
?x vcard:FN ?name
}
WHERE {
?x foaf:name ?name .
}
ASK odpověď je datového typu boolean;
# https://www.w3.org/TR/2013/REC-sparql11-query-20130321/#ask
# příklad 1 - odpověď bude ’true’ nebo ’false’?
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
ASK { ?x foaf:name "Alice" }
# příklad 2 - odpověď bude ’true’ nebo ’false’?
PREFIX vcard: <http://www.w3.org/2001/vcard-rdf/3.0#>
ASK { ?x vcard:FN "Alice" }
- hodnota
true, pokud vzor dotazu vyhovuje nějaké odpovědi,
- jinak
false.
DESCRIBE vrací RDF graf popisující zdroj
# https://www.w3.org/TR/2013/REC-sparql11-query-20130321/#describe
# příklad 1 - známe URI
DESCRIBE <abc>
# příklad 2 - neznáme konkrétní URI
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
DESCRIBE ?x
WHERE {
?x foaf:name "Alice" .
}
SPARQL – řešené příklady
Schéma dat v systému MRE
Data vychází z datového formátu DASTA (DAtový STAndard) spravovaný Ministerstvem zdravotnictví ČR
V systému MRE používané ontologie jsou dokumentovány:
https://mre.zcu.cz/ontology/ontologies.html
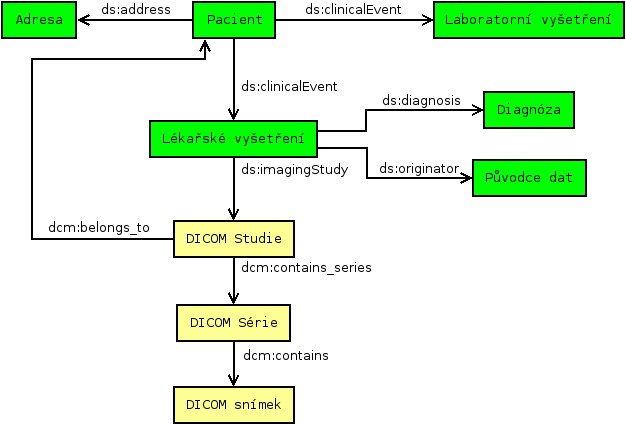
V našem případě jsou:
- schéma vybraných tříd a vlastností viz obrázek níže.
- data formátu DASTA transformována do RDF.
- schéma popisují číselníky a ontologie
-
DASTA Ontology (prefix ds)
-
Číselník DASTA (prefix dscl)
-
DICOM Ontology (prefix dcm) – aktuálně používaná ontologie pro popis obrazových vyšetření ve formátu DICOM
- dokumentace http://mre.kiv.zcu.cz/ontology/dicom
dicom.owl http://mre.kiv.zcu.cz/ontology/dicom.owl- Základem je třída Patient (
dcm:Patient), k němuž se může vztahovat několik DICOM studií (dcm:Study).
- Každá DICOM studie je složena z několika sérií (
dcm:Series).
-
DICOM série obsahuje/je složena z konkrétních snímků (
dcm:CT_Image) obrazového vyšetření,
např. počítačová tomografie (CT), magnetická rezonance (MR).
- Existuje také ontologie SEDI (SEmantic DIcom).
-
SITS Ontology – ontologie inspirovaná mezinárodním registrem Safe Implementation of Treatments in Stroke
(SITS) pro sledování průběhu a výsledku léčby pacientů pro cévní mozkové příhodě.
Schéma vybraných tříd a vlastností v systému MRE
Připravená RDF data
patient1-medical
- 1 pacient se jménem
Anon_666,
- 45 RDF trojic.
patient6-medical
- zahrnuje celkem 6 pacientů, včetně pacienta z
patient1-medical,
- 24 730 RDF trojic.
patient7-medical
- zahrnuje celkem 7 pacientů,
- přidán jeden pacient oproti předchozímu
patient6-medical,
- 25 011 RDF trojic.
patient7-imaging
- data popisující obrazová vyšetření jednoho pacienta, který je součástí předchozího
patient7-medical,
- 33 158 RDF trojic.
Použité datové formáty (koncovka):
nt N-TRIPLE
ttl TURTLE
xml RDF/XML
Používané jmenné prostory
PREFIX id: <http://mre.zcu.cz/id/>
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
PREFIX dscl: <http://mre.zcu.cz/ontology/dscl.owl#>
PREFIX dcm: <http://mre.zcu.cz/ontology/dcm.owl#>
PREFIX sits: <http://mre.zcu.cz/ontology/sits.owl#>
PREFIX nihss: <http://mre.zcu.cz/ontology/nihss.owl#>
PREFIX mre: <http://mre.zcu.cz/ontology/mre.owl#>
PREFIX acl: <http://www.w3.org/ns/auth/acl#>
PREFIX dc: <http://purl.org/dc/elements/1.1/>
PREFIX nfo: <http://www.semanticdesktop.org/ontologies/2007/03/22/nfo#>
PREFIX owl: <http://www.w3.org/2002/07/owl#>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
Kompletní výčet a detaily viz https://mre.zcu.cz/ontology/ontologies.html.
SPARQL Server – Apache Fuseki
Stáhněte si program z adresy https://jena.apache.org/download/, rozbalte jej
a z rozbaleného adresáře spusťte
-
v Linuxu:
./fuseki-server
-
ve Windows:
fuseki-server.bat
a následně v konzoli uvidíme start serveru. Server běží ve výchozím nastavení na portu 3030.
Ve webovém prohlížeči zadáme adresu: http://localhost:3030
a vše je připraveno k nahrání dat a zkoušení příkladů.
Data příkladů – pacient Anon_666
id:cd3f0c85b158c08a2b113464991810cf2cdfc387
a ds:Patient , ds:Male ;
ds:address id:3840aecb9edac9f7d7c9172f2f4be82b08ab3ddf ;
ds:clinicalEvent id:be8d011f882326495f8d06c58f22db51d95cc7bf ;
ds:datetimeBirth "1938-08-13"^^xsd:date ;
ds:lastName "Anon_666" ;
ds:patientID "666" ;
ds:sex "M" ;
ds:sexNCLPTPS dscl:NCLPTPS_M ;
ds:sexPOHLAV dscl:POHLAV_1 ;
dc:title "Anon_666 (M) * 1938-08-13" .
id:3840aecb9edac9f7d7c9172f2f4be82b08ab3ddf
a ds:PermanentAddress ;
ds:addressCity "Město 1" ;
ds:addressZIP "00001" ;
dc:title "Město 1 (00001)" .
id:be8d011f882326495f8d06c58f22db51d95cc7bf
a ds:MedicalExamination ;
ds:datetimeEvent "2012-09-19T23:20:00+0200"^^xsd:dateTime ;
ds:diagnosis id:2c545600eb7a2722809d64c2753de714a5154b6b ,
id:2285692c932c88f8673a162ef7b5c997993da41c ;
ds:dsclExaminationContent dscl:LZSOZ_NL ;
ds:dsclExaminationOrigin dscl:LZTOZV_J ;
ds:dsclExaminationRequest dscl:LZTZOV_D ;
ds:dsclExaminationState dscl:LZSZZ_K ;
ds:imagingStudyNumber "00000078" ;
ds:originator id:44040e7024d5a4cc177bf0ed29683c2185dbd05b ;
ds:reportText "CT mozku:..." ;
ds:reportTitle "032/002 - CT mozku: s k.l. iv." ;
dc:title "2012-09-19 23:20: 032/002 - CT mozku: s k.l. iv." .
id:2c545600eb7a2722809d64c2753de714a5154b6b
a ds:ActualDiagnosis ;
ds:datetimeEvent "2012-04-18"^^xsd:date ;
ds:diagCode dscl:MKN10_5_J180 ;
ds:diagDetail "Bronchopneumonie NS" ;
ds:diagOrder 1 ;
ds:patient id:cd3f0c85b158c08a2b113464991810cf2cdfc387 ;
dc:title "2012-04-18 (1) J18.0 - Bronchopneumonie NS" .
id:2285692c932c88f8673a162ef7b5c997993da41c
a ds:ActualDiagnosis ;
ds:datetimeEvent "2012-04-18"^^xsd:date ;
ds:diagCode dscl:MKN10_5_I639 ;
ds:diagDetail "Mozkový infarkt" ;
ds:diagOrder 2 ;
ds:patient id:cd3f0c85b158c08a2b113464991810cf2cdfc387 ;
dc:title "2012-04-18 (2) I63.9 - Mozkový infarkt" .
id:44040e7024d5a4cc177bf0ed29683c2185dbd05b
a ds:OriginatorDepartment ;
ds:departmentName "Nemocnice na ..." ;
dc:title "Nemocnice na ..." .
Jednoduché dotazy
Všechny existující trojice
Níže uvedené dotazy budou aplikovány nad datovou sadou patient1-medical.
Chceme-li získat všechny trojice, musíme v části WHERE mít vzor trojice se třemi proměnnými.
Ty vyhovují všem trojicím. V části SELECT je uvedeme.
# základní forma dotazu SELECT
# 01a
SELECT ?subject ?predicate ?object
WHERE {
?subject ?predicate ?object .
}
# na názvech proměnných nezáleží, jsou oddělovány jen mezerou
# 01b
SELECT ?s ?p ?o
WHERE {
?s ?p ?o .
}
Dotaz vrátí všechny trojice, tj. tři sloupce s hodnotami dle celkového počtu trojic v datasetu.
Omezení počtu lze provést použitím klíčového slova LIMIT.
# 02
SELECT ?s ?p ?o
WHERE {
?s ?p ?o
}
LIMIT 10
Dotaz vrátí 10 trojic ve třech sloupcích odpovídajících trojicím. Vedle LIMIT, lze použít také OFFSET.
Všechny vlastnosti a hodnoty pro zadané URI
- Známe URI.
- Zajímají nás všechny vlastnosti a jejich hodnoty.
# získání všech vlastností a jejich hodnot SELECTem
# 03a
SELECT ?p ?o
WHERE {
<http://mre.zcu.cz/id/cd3f0c85b158c08a2b113464991810cf2cdfc387> ?p ?o .
}
# s využitím prefixu v zápisu
# 03b
PREFIX id: <http://mre.zcu.cz/id/>
SELECT ?p ?o
WHERE {
id:cd3f0c85b158c08a2b113464991810cf2cdfc387 ?p ?o .
}
Výsledkem dotazu je 11 dvojic (pár vlastnost a její hodnota) pro výše uvedené URI.
V podobě grafu lze prakticky totéž získat prostřednictvím DESCRIBE:
# získání všech vlastností a jejich hodnot příkazem DESCRIBE
# 03c
PREFIX id: <http://mre.zcu.cz/id/>
DESCRIBE id:cd3f0c85b158c08a2b113464991810cf2cdfc387
Vrátí RDF graf s 11 trojicemi, které mají jako subjekt uvedené URI.
Rodné číslo pacienta pro známé URI
- Známe URI zdroje (subjekt)
- Známe vlastnost s rodným číslem pacienta (
ds:patientID)
- Zajímá nás hodnota rodného čísla
# získání hodnot(y) vybrané vlastnosti
# 04a
PREFIX id: <http://mre.zcu.cz/id/>
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
SELECT ?o
WHERE {
id:cd3f0c85b158c08a2b113464991810cf2cdfc387 ds:patientID ?o .
}
# přejmenování proměnné na ?rc
# 04b
PREFIX id: <http://mre.zcu.cz/id/>
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
SELECT ?rc
WHERE {
id:cd3f0c85b158c08a2b113464991810cf2cdfc387 ds:patientID ?rc .
}
Dotaz vrátí jeden řádek s jednou hodnotou (jeden sloupec). V části WHERE může být i celé URI bez zkrácení prefixem.
Hodnota vlastnosti ds:patientID bude svázána (bind) s proměnnou ?rc a dostupná jako výsledek v části SELECT.
URI pacienta pro známé rodné číslo
- Známe vlastnost s rodným číslem pacienta (
ds:patientID).
- Známe hodnotu – rodné číslo.
- Zajímá nás URI pacienta (zdroje, subjekt).
# získání subjectu (pacienta) na základě znalosti jeho rč
# 05
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
SELECT ?patient
WHERE {
?patient ds:patientID "666" .
}
Výsledkem dotazu je jedna hodnota URI.
URI všech pacientů a jejich rodných čísel
Níže uvedené dotazy budou aplikovány nad datovou sadou patient6-medical.
- Známe URI vlastnosti pro rodné číslo
ds:patientID.
- Zajímá nás URI zdroje a hodnota vlastnosti.
# získání identifikace pacienta a jeho rč
# 06
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
SELECT ?pacient ?rc
WHERE {
?pacient ds:patientID ?rc .
}
Výsledkem dotazu je šest hodnot URI a rodných čísel.
Rodné číslo a jméno pro zadané URI pacienta
- Můžeme použít více vzorů trojic s proměnnou.
- Pro stejné zdroje lze mít více tvrzení oddělených středníkem (viz Turtle) v části
WHERE.
- Pro vypsání hodnot umístíme proměnnou v části
SELECT.
# každá vlastnost tvoří jednu RDF trojici ve WHERE
# 07a
PREFIX id: <http://mre.zcu.cz/id/>
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
SELECT ?rc ?jmeno
WHERE {
id:cd3f0c85b158c08a2b113464991810cf2cdfc387 ds:patientID ?rc .
id:cd3f0c85b158c08a2b113464991810cf2cdfc387 ds:lastName ?jmeno .
}
# vlastnosti ke stejnému zdroji jsou oddělené středníkem
# 07b
PREFIX id: <http://mre.zcu.cz/id/>
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
SELECT ?rc ?jmeno
WHERE {
id:cd3f0c85b158c08a2b113464991810cf2cdfc387
ds:patientID ?rc ;
ds:lastName ?jmeno .
}
V obou příkladech dostaneme stejný výsledek.
Jméno a rodné číslo všech pacientů
# v dalších dotazech budeme využívat zkráceného zápisu
# 08a
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
SELECT ?pacient ?rc ?jmeno
WHERE {
?pacient ds:patientID ?rc ;
ds:lastName ?jmeno .
}
a použijeme hvězdičku (*), chceme-li zobrazit všechny proměnné:
# použitá * pro vypsání všech proměnných
# 08b
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
SELECT *
WHERE {
?pacient ds:patientID ?rc ;
ds:lastName ?jmeno .
}
Datum narození a úmrtí pacientů
- Chceme k rodnému číslu a jménu pacienta získat další hodnoty.
- Datum narození má vlastnost
ds:datetimeBirth
- Datum úmrtí má vlastnost
ds:datetimeDeath
# nejdříve dohledáme datum narození
# 09a
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
SELECT *
WHERE {
?pacient ds:patientID ?rc ;
ds:lastName ?jmeno ;
ds:datetimeBirth ?narozeni .
}
# a potom datum úmrtí
# 09b
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
SELECT *
WHERE {
?pacient ds:patientID ?rc ;
ds:lastName ?jmeno ;
ds:datetimeBirth ?narozeni ;
ds:datetimeDeath ?umrti .
}
Jaký je výsledek dotazu? Proč? Správné řešení:
# datum úmrtí je nepovinný - přidáme konstrukci OPTIONAL
# 09c
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
SELECT *
WHERE {
?pacient ds:patientID ?rc ;
ds:lastName ?jmeno ;
ds:datetimeBirth ?narozeni .
OPTIONAL {
?pacient ds:datetimeDeath ?umrti .
}
}
Výsledek (počet řádek) dle zvoleného příkladu:
- 1 pro
patient1-medical,
- 6 pro
patient6-medical,
- 7 pro
patient7-medical.
# pozor - pokud je proměnná prvně zavedena v konstrukci OPTIONAL
# a až následně použita ve zbytku vzoru, výsledek se změní.
# 09d
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
SELECT *
WHERE {
OPTIONAL {
?pacient ds:datetimeDeath ?umrti .
}
?pacient ds:patientID ?rc ;
ds:lastName ?jmeno ;
ds:datetimeBirth ?narozeni .
}
Význam klíčového slova OPTIONAL – ovlivní počet výsledků.
Rodná čísla a jména pacientů s rodným číslem větším než 200
Filtrování hodnoty rodného čísla:
# filtrační podmínka - volání funkce FILTER
# 10a
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
SELECT *
WHERE {
?pacient ds:patientID ?rc ;
ds:lastName ?jmeno ;
ds:datetimeBirth ?narozeni .
OPTIONAL {
?pacient ds:datetimeDeath ?umrti .
}
FILTER ( ?rc > 200 )
}
Všechny hodnoty rodného čísla porovná s filtrem. Funguje?
Hodnota ds:patientID je string, nikoliv číslo, porovnáváme text s číslem.
# převedem hodnotu rc na číslo
# 10b
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
SELECT *
WHERE {
?pacient ds:patientID ?rc ;
ds:lastName ?jmeno ;
ds:datetimeBirth ?narozeni .
OPTIONAL {
?pacient ds:datetimeDeath ?umrti .
}
FILTER ( ?rc > "200" )
}
Asi to funguje. Opravdu?
# změního hodnotu rc na 20
# 10c
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
SELECT *
WHERE {
?pacient ds:patientID ?rc ;
ds:lastName ?jmeno ;
ds:datetimeBirth ?narozeni .
OPTIONAL {
?pacient ds:datetimeDeath ?umrti .
}
FILTER ( ?rc > "20" )
}
Proč to přestalo fungovat? Odpovědí je lexikografické řazení. Řešení: musíme na číslo přetypovat hodnotu rc.
# nutné přetypování rc na číslo
# 10d
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
SELECT *
WHERE {
?pacient ds:patientID ?rc ;
ds:lastName ?jmeno ;
ds:datetimeBirth ?narozeni .
OPTIONAL {
?pacient ds:datetimeDeath ?umrti .
}
FILTER ( xsd:int(?rc) > 200 )
}
Pacienti seřazeni dle rodného čísla
Obdoba předchozích příkladů, jen je navíc požadováno řazení:
# řazení pacientů podle jejich rc - ORDER BY
# 11a
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
SELECT *
WHERE {
?pacient ds:patientID ?rc ;
ds:lastName ?jmeno ;
ds:datetimeBirth ?narozeni .
OPTIONAL {
?pacient ds:datetimeDeath ?umrti .
}
}
ORDER BY DESC (?rc)
# stejný problém jako u funkce FILTER
# 11b
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
SELECT *
WHERE {
?pacient ds:patientID ?rc ;
ds:lastName ?jmeno ;
ds:datetimeBirth ?narozeni .
OPTIONAL {
?pacient ds:datetimeDeath ?umrti .
}
}
ORDER BY DESC ( xsd:int(?rc) )
Vhodné použít data patient6-medical nebo patient7-medical. Výsledek dotazu (počet řádek) dle zvoleného příkladu:
- 1 pro
patient1-medical,
- 6 pro
patient6-medical,
- 7 pro
patient7-medical
Porovnejte různé varianty části ORDER BY – rozdíl mezi znakovým a číselným řazením:
ORDER BY ?rc
ORDER BY ASC ( ?rc )
ORDER BY DESC ( ?rc )
ORDER BY DESC ( xsd:int(?rc) )
ORDER BY ?jmeno DESC ( ?rc )
Výsledek dotazu lze ovlivnit modifikátorem ORDER BY pro řazení, ASC, DESC určují směr řazení.
V případě chybějícího datového typu se jedná obecně o string:
- proto je řazení implicitně znakové,
- chceme-li řadit číselně, je nutné doplnit přetypování:
xsd:int(?rc).
Pacienti s datem narození v určeném období
Pacienti narozeni od 1. ledna 1930 do současnosti.
# pacienti narozeni 1.1.1930 a dříve
# 12a
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
SELECT *
WHERE {
?pacient ds:patientID ?rc ;
ds:lastName ?jmeno ;
ds:datetimeBirth ?narozeni .
OPTIONAL {
?pacient ds:datetimeDeath ?umrti .
}
FILTER ( ?narozeni >= "1930-01-01" )
}
Ve filtru uvedeme i datový typ hodnoty:
# funguje s uvedením datového typu hodnoty
# 12b
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
SELECT *
WHERE {
?pacient ds:patientID ?rc ;
ds:lastName ?jmeno ;
ds:datetimeBirth ?narozeni .
OPTIONAL {
?pacient ds:datetimeDeath ?umrti .
}
FILTER ( ?narozeni >= "1930-01-01"^^xsd:date )
}
Pacienti narozeni ve 30. letech 20. století.
# více FILTERů je spojeno implicitně AND
# 13a
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
SELECT *
WHERE {
?pacient ds:patientID ?rc ;
ds:lastName ?jmeno ;
ds:datetimeBirth ?narozeni .
OPTIONAL {
?pacient ds:datetimeDeath ?umrti .
}
FILTER ( ?narozeni >= "1930-01-01"^^xsd:date )
FILTER ( ?narozeni <= "1939-12-31"^^xsd:date )
}
# složitější logická podmínka ve FILETRu
# 13b
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
SELECT *
WHERE {
?pacient ds:patientID ?rc ;
ds:lastName ?jmeno ;
ds:datetimeBirth ?narozeni .
OPTIONAL {
?pacient ds:datetimeDeath ?umrti .
}
FILTER ( ?narozeni >= "1930-01-01"^^xsd:date &&
?narozeni <= "1939-12-31"^^xsd:date )
}
Pacienti bez uvedeného data úmrtí
Konstrukcí EXISTS můžeme testovat, zda daný grafový vzor lze najít v datech. Chceme-li výsledek negovat, aplikujeme operátor NOT.
# pacienti, kteří nemají uveden datum úmrtí - NOT EXISTS
# 14a
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
SELECT *
WHERE {
?pacient ds:patientID ?rc ;
ds:lastName ?jmeno ;
ds:datetimeBirth ?narozeni .
FILTER ( NOT EXISTS {
?pacient ds:datetimeDeath ?umrti .
} )
}
Srovnatelného výsledku dosáhneme voláním logické funkce BOUND, která testuje, zda proměnná má hodnotu nebo ne.
Negaci funkce dosáhneme operátorem !
# pacienti, kteří mají uveden datum úmrtí - BOUND
# 14b
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
SELECT *
WHERE {
?pacient ds:patientID ?rc ;
ds:lastName ?jmeno ;
ds:datetimeBirth ?narozeni .
OPTIONAL {
?pacient ds:datetimeDeath ?umrti .
}
FILTER (BOUND (?umrti))
}
# pacienti, kteří nemají uveden datum úmrtí - negace BOUND
# 14c
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
SELECT *
WHERE {
?pacient ds:patientID ?rc ;
ds:lastName ?jmeno ;
ds:datetimeBirth ?narozeni .
OPTIONAL {
?pacient ds:datetimeDeath ?umrti .
}
FILTER (! BOUND (?umrti))
}
Dožitý věk pacientů
Z předchozích dotazů víme, že 2 pacienti jsou již po smrti. Proto jim můžeme spočítat věk, kterého se dožili.
Každý výraz v klauzuli SELECT musí být doplněn o alias a celý zápis odvozeného sloupce musí být uzavřen v závorce.
# u pacienta chceme spočítat, jakého věku se dožil
# potřebujeme odvozený sloupec
# 15a
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
SELECT ?rc
?jmeno
?narozeni
?umrti
((?umrti - ?narozeni) AS ?vek)
WHERE {
?pacient ds:patientID ?rc ;
ds:lastName ?jmeno ;
ds:datetimeBirth ?narozeni ;
ds:datetimeDeath ?umrti .
}
Vypočtený výsledek je ve dnech, chceme spočítat léta.
# spočítáme dožitý věk v letech
# 15b
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
SELECT ?rc
?jmeno
?narozeni
?umrti
(FLOOR (DAY (?umrti - ?narozeni) / 365) AS ?vek)
WHERE {
?pacient ds:patientID ?rc ;
ds:lastName ?jmeno ;
ds:datetimeBirth ?narozeni ;
ds:datetimeDeath ?umrti .
}
Pokud bychom chtěli filtrovat jen ty pacienty, kteří se dožili 80 let a více, tak máme smůlu.
Potom je potřeba využít funkce BIND.
# u pacienta chceme spočítat, jakého věku se dožil
# potřebujeme odvozený sloupec - BIND
# 15c
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
SELECT *
WHERE {
?pacient ds:patientID ?rc ;
ds:lastName ?jmeno ;
ds:datetimeBirth ?narozeni ;
ds:datetimeDeath ?umrti .
BIND (FLOOR (DAY (?umrti - ?narozeni) / 365) AS ?vek)
}
Filtrace 80 letých pacientů je snadná funkcí FILTER.
# nad takto odvozenou hodotou můžeme stanovit filtrační podmínku
# 15d
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
SELECT *
WHERE {
?pacient ds:patientID ?rc ;
ds:lastName ?jmeno ;
ds:datetimeBirth ?narozeni ;
ds:datetimeDeath ?umrti .
BIND (FLOOR (DAY (?umrti - ?narozeni) / 365) AS ?vek)
FILTER ( ?vek > 80 )
}
URI všech instancí třídy aktuálního pacienta
- Aktuální pacient má třídu
ds:Patient.
- Typ instance je určen vlastností
rdf:type.
# získání URI patřící jen pacientům
# 16a
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
SELECT ?pacient
WHERE {
?pacient rdf:type ds:Patient .
}
Vlastnost rdf:type lze zkracovat na prosté písmeno „a“.
# existuje zkratka, nevyžadující prefix rdf - a
# 16 b
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
SELECT ?pacient
WHERE {
?pacient a ds:Patient .
}
Třídy instancí pacientů
- Pacient má jméno dostupné přes
ds:lastName.
- Pacient nemusí být jen instancí třídy
ds:Patient.
# ověřme, do jakých tříd (typů) nám spadají všechny uzly (URI), které mají jméno
# 17
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
SELECT ?uzel ?trida
WHERE {
?uzel a ?trida ;
ds:lastName ?jmeno .
}
Zjistili jsme, že každý pacient je navíc instancí třídy ds:Male nebo ds:Female, což odpovídá pohlaví pacienta.
Zjistěme, který pacient ma jaké pohlaví prostřednictvím dané třídy.
# získat identifikátory uzlů, které mají jméno a spadají do třídy ds:Male nebo ds:Female
# 18a
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
SELECT ?uzel ?jmeno ?trida
WHERE {
?uzel a ?trida ;
ds:lastName ?jmeno .
FILTER (?trida = ds:Female || ?trida = ds:Male)
}
Konstrukcí VALUES lze naplnit proměnnou nebo n-tici proměnných s přesně definovanou sadou hodnot.
Pokud je takto zavedená proměnná dále použita ve WHERE klauzuli, nemůže nabývat jiných hodnot.
# to samé pomocí VALUES
# 18b
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
SELECT ?uzel ?jmeno ?pohlavi
WHERE {
VALUES ?pohlavi { ds:Female ds:Male }
?uzel a ?pohlavi ;
ds:lastName ?jmeno .
}
# místo názvu třídy vypíšeme statický řetězec
# 18c
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
SELECT ?uzel ?jmeno ?pohlavi
WHERE {
VALUES (?typ ?pohlavi) { (ds:Female "Žena") (ds:Male "Muž") }
?uzel a ?typ ;
ds:lastName ?jmeno .
}
Četnosti pacientů dle pohlaví
Na základě znalosti, jaké pohlaví má který pacient, můžeme s využitím agregačních funkcí spočítat, kolik pacientů je žen a kolik je mužů.
# následně si uděláme malou statistiku pacientů podle jejich pohlaví - GROUP BY
# 19
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
SELECT ?pohlavi
(COUNT (?uzel) AS ?pocet)
WHERE {
VALUES (?typ ?pohlavi) { (ds:Female "Žena") (ds:Male "Muž") }
?uzel a ?typ ;
ds:lastName ?jmeno .
}
GROUP BY ?pohlavi
Ověření získaných znalostí
Použijte zejména data patient7-medical a ověřte, že vaše dotazy vrací správné výsledky pro níže uvedené příklady.
-
Příklad 20-1a – Pro všechny pacienty vypište hodnoty sloupců:
- rodné číslo,
- jméno,
- datum narození,
- datum úmrtí,
- pohlaví (pouze písmeno M nebo F),
- anotace zdroje (instance) z
dc:title a současně i rdfs:label,
- numericky seřaďte vzestupně dle rodného čísla.
- Příklad 20-1b – Upravte příklad 20-1a omezením výčtu pacientů pouze na jednoho explicitním zadáním URI.
- Příklad 20-1c – Upravte příklad 20-1a omezením výčtu pacientů na min. dva nebo tři pacienty zadané prostřednictvím známého URI.
-
Příklad 20-2 – Upravte příklad 20-1a omezením na pacienty mužského pohlaví prostřednictvím:
- filtru hodnoty (20-2a),
- instance pacientů třídy
ds:Male (20-2b).
Průchod grafu
Doporučená data: patient7-medical.
Jméno a rodné číslo pacientů společně s datem a časem z lékařské zprávy
- Vypsat informace o pacientovi – jméno, rodné číslo.
- Vypsat datum a čas lékařské zprávy.
# jméno a rč pacienta včetně data jeho lékařských vyšetření
# 21a
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
SELECT ?rc
?jmeno
?datum
WHERE {
?pacient a ds:Patient ;
ds:patientID ?rc ;
ds:lastName ?jmeno ;
ds:clinicalEvent ?vysetreni .
?vysetreni ds:datetimeEvent ?datum .
}
Dotaz vrací 1 013 výsledků. Je to správně? Není, opakují se nám stejné kombinace hodnot.
# ve výsledku se nám opakují hodnoty - použijeme DISTINCT
# 21a
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
SELECT DISTINCT ?rc
?jmeno
?datum
WHERE {
?pacient a ds:Patient ;
ds:patientID ?rc ;
ds:lastName ?jmeno ;
ds:clinicalEvent ?vysetreni .
?vysetreni ds:datetimeEvent ?datum .
}
Přidáním DISTINCT za SELECT omezíme počet duplicitních výsledků a dostaneme 47 výsledků. Je to už správně?
Nevíme, uděláme si kontrolu. Nejdříve zjistíme, kolik existuje instancí třídy ds:MedicalExamination:
# 22a
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
SELECT ?uri
WHERE {
?uri a ds:MedicalExamination .
}
nebo prostřednictvím agregační funkce COUNT():
# 22b
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
SELECT ( COUNT(?uri) as ?pocet )
WHERE {
?uri a ds:MedicalExamination .
}
V obou případech je celkový počet 10 lékařských zpráv. Ve skutečnosti může být v ds:clinicalEvent:
- lékařská zpráva (
ds:MedicalExamination),
- i výsledky laboratorního vyšetření (
ds:LaboratoryReport).
Má-li být výstupem pouze datum a čas lékařských zpráv, musíme doplnit trojici, která specifikuje typ (třídu).
# problém je jinde, poskytuje to jak lékařská vyšetření, tak laboratorní vyšetření
# 21b
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
SELECT ?rc
?jmeno
?datum
WHERE {
?pacient a ds:Patient ;
ds:patientID ?rc ;
ds:lastName ?jmeno ;
ds:clinicalEvent ?vysetreni .
?vysetreni ds:datetimeEvent ?datum ;
a ds:MedicalExamination .
}
Nyní dotaz vrací správně 10 výsledků (stejně to bude v tomto případě s DISTINCT pro uvedená data).
Přidání trojice s určením typu třídy odstraní všechny ostatní instance ds:LaboratoryReport, které nás zrovna nezajímají.
Diagnózy pacientů
Diagnóza je vždy uvedena u lékařské zprávy pacienta:
# zjistíme, jaké diagnózy byly určeny během lékařských vyšetření
# diagnózy jsou dostupné jen přes lékařská vyšetření
# 23a
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
SELECT ?rc
?jmeno
?popis
WHERE {
?pacient a ds:Patient ;
ds:patientID ?rc ;
ds:lastName ?jmeno ;
ds:clinicalEvent ?vysetreni .
?vysetreni ds:diagnosis ?diagnoza .
?diagnoza ds:diagDetail ?popis .
}
ORDER BY ?jmeno ?popis
Ve výsledku je patrné, že se nám některé diagnózy u stejného pacieta opakují. To je dáno skutečností, že stejná diagnóza byla u pacienta
znova detekována na dalším vyšetření. Zjistíme, kolikrát byla každá diagnóza detekována u každého pacienta:
# kolikrát byla která diagnóza určena během lékařského vyšetření
# 23b
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
SELECT ?rc
?jmeno
(COUNT (?diagnoza) AS ?pocet)
?popis
WHERE {
?pacient a ds:Patient ;
ds:patientID ?rc ;
ds:lastName ?jmeno ;
ds:clinicalEvent ?vysetreni .
?vysetreni ds:diagnosis ?diagnoza .
?diagnoza ds:diagDetail ?popis .
}
GROUP BY ?rc ?jmeno ?popis
ORDER BY ?jmeno ?popis
Výsledek dotazu je 34 diagnóz pro data z patient7-medical. V dotazu musíme projít od pacienta ?patient
(získáme jeho rodné číslo a jméno) na klinickou událost (?vysetreni), z klinické události ?vysetreni projdeme
k diagnóze ?diagnoza a z diagnózy nás zajímá její popis.
Ke stejnému výsledku dojdeme také při využití Property Path ve SPARQL 1.1:
# získání popisu diagnózy pomocí Property Path
# 23c
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
SELECT ?rc
?jmeno
(COUNT (?diagnoza) AS ?pocet)
?popis
WHERE {
?pacient a ds:Patient ;
ds:patientID ?rc ;
ds:lastName ?jmeno ;
ds:clinicalEvent/ds:diagnosis ?diagnoza .
?diagnoza ds:diagDetail ?popis .
}
GROUP BY ?rc ?jmeno ?popis
ORDER BY ?jmeno ?popis
Ověření získaných znalostí
- Je chybou, že zde není v příkladech 23b a 23c uvedena třída – rdf:type (
ds:MedicalExamination)?
- Dotazem zjistěte, kolik je v datech
patient7-medical instancí ds:LaboratoryReport?
- Doplňte do 23b nebo 23c omezení, abychom získali pouze hlavní diagnózy (mají hodnotu 1 ve vlastnosti
ds:diagOrder).
- Co je potřeba v datech změnit/přidat, abychom v předchozí úloze nepotřebovali použít
FILTER?
- Podívejte se na data (na schéma výše není uvedeno) a najděte další způsob, jak jinak vypsat stejné výsledky. Vytvořte odpovídající dotaz.
Typy dotazů
Dotazovací jazyk SPARQL nabízí kromě příkazu SELECT ještě další dva příkazy pro dotazování: DESCRIBE a ASK.
Příkazy SELECT a ASK vyžadují konstrukci FROM, u příkazu DESCRIBE je tato konstrukce nepovinná.
Příkaz DESCRIBE pro všechny proměnné mající tvar URI vrací všechny RDF troji těchto identifikátorů.
Chceme-li znát všechny vlastnosti a jejich hodnoty daného identifikároru, použijeme k tomu tento příkaz.
Naproti tomu příkaz ASK poskytuje jen odpovědi True nebo False na otázku, zda dané trojice jsou v datové sadě dostupné či nikoliv.
V uvedených trojicích se mohou vyskytovat proměnné, pak probíhá dosazování různých hodnot za tyto proměnné.
Porovnejte výsledky níže uvedených dotazů, které mají shodnou konstrukci WHERE:
# příkaz SELECT
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
SELECT *
WHERE {
?pacient a ds:Patient .
?pacient ds:patientID "666" .
?pacient ds:clinicalEvent ?vysetreni .
}
# příkaz DESCRIBE
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
DESCRIBE *
WHERE {
?pacient a ds:Patient .
?pacient ds:patientID "666" .
?pacient ds:clinicalEvent ?vysetreni .
}
# příkaz ASK
PREFIX ds: <http://mre.zcu.cz/ontology/dasta.owl#>
ASK
WHERE {
?pacient a ds:Patient .
?pacient ds:patientID "666" .
?pacient ds:clinicalEvent ?vysetreni .
}
Samostatné úlohy
DISTINCT,FILTER,VALUES,- agregační funkce,
GROUP BY,HAVING,- a další
Pro následující úlohy použijte současně data patient7-medical a patient7-imaging.
Můžete je nahrát:
- do jednoho datasetu (výchozího grafu) jako doposud
-
nebo do dvou samostatných grafů, které si vhodně pojmenujete.
- V dotazech musíte specifikovat, nad kterým grafem/grafy se dotazujete v části
FROM.
Úlohy
-
Vyberte datum s časem všech laboratorních výsledků bez duplicit a seřazené od nejnovějších k nejstarším.
- Řešení má být 37 výsledků.
-
Najděte a vypište všechny URI diagnóz, které jsou v datech použity (
ds:DiagCode) a abecedně je seřaďte.
- Řešení má být 29 výsledků.
-
Zjistěte počet DICOM studií (
dcm:Study)?
- Řešení má být jeden výsledek s hodnotou 1 (DICOM studií).
-
Zjistěte, jakým pacientům a které DICOM studie patří – uveďte jeho rodné číslo
ds:patientID a číslo studie dcm:Study_ID.
- Řešení má být jeden výsledek s pacientem 592 a studií 832.
-
Zjistěte počet DICOM sérií (
dcm:Series)?
- Řešení má být jeden výsledek s hodnotou 10 (DICOM sérií).
-
Zjistěte počet DICOM snímků (
dcm:CT_Image)?
- Řešení má být jeden výsledek s hodnotou 550 (DICOM snímků).
-
Zjistěte z kolika DICOM souborů (snímků
dcm:CT_Image) se každá ze sérií skládá, a seřaďte je od největší k nejmenší?
Vypište číslo série (dcm:Series_Number), popis (dcm:Series_Description) a počet souborů v sérii.
- Řešení má být 7 výsledků (sérií) s počty souborů: 304, 116, 70, 31, 24, 4 a 1.
-
Zjistěte z kolika DICOM souborů (snímků
dcm:CT_Image) se každá ze sérií skládá, a jaký objem dat na disku zabírá?
Vypište číslo série (dcm:Series_Number), popis (dcm:Series_Description), počet souborů v sérii, celkovou velikost série v B i současně v MB.
Hodnotu velikosti v MB zaokrouhlete. Série seřaďte dle velikosti v Bytech.
- Řešení má být 7 výsledků (sérií) s velikostmi (MB): 156, 59, 35, 16, 12, 1 a 0.
-
Najděte laboratorní výsledky, jejichž hodnoty (
ds:labNumberValue) jsou mimo stanovené referenční meze pro daného pacienta:
ds:labScale4 je referenční mez dolní,ds:labScale5 je referenční mez horní,
a vypište unikátní název naměřené veličiny (ds:labLocalName), hodnotu, a obě referenční meze.
Data budou řazena vzestupně dle názvu, dolní meze, hodnoty a horní meze.
-
Neuvažujte datum laboratorního výsledku.
- Řešení má být 171 výsledků.
-
Uvažujte datum laboratorního výsledku. Zobrazen bude bezprostředně za názvem.
Stejně tak u řazení, nejprve název a pak dle data, následovat budou zbývající hodnoty.
- Řešení má být 216 výsledků.
-
Zjistěte, kolikrát byly laboratorní hodnoty (název,
ds:labLocalName) mimo stanovené meze.
Zobrazit pouze ty, které se opakují (alespoň 2x) a seřadit dle počtu (sestupně) a názvů (vzestupně).
- Řešení má být 25 výsledků. (Celkem je hodnot mimo referenční meze 47.)
Copyright © 2023 Petr Včelák a Martin Zíma