Table of Contents
problematika je značně složitější než jen vstup a výstup akcentovaných znaků:
vstup a výstup akcentovaných znaků ale i dalších speciálních znaků
použití akcentovaných znaků ve zdrojových kódech (I/O, dokumentační komentáře, ...)
převod velkých písmen na malá a naopak
řazení řetězců podle pravidel abecedního řazení národního jazyka
formátování čísel
práce s datumem a časem, měnou apod.
používané zkratky:
i18n – i
nternationalizationpsaní programu tak, aby se dal snadno přizpůsobit libovolnému národnímu prostředí
l10n – l
ocalizationpřevedení programu do dané jazykové mutace
národní zváštnosti nemají být řešeny “natvrdo” ve zdrojovém kódu
popsat v konfiguračních souborech (viz poslední část přednášky)
využívat služeb operačního systému
řešení problémů typu řazení, formátování čísel, datumů apod.
využívat specializované třídy/metody z Java Core API respektující národní zvyklosti
podrobný rozbor viz Java Tutorial
Note
Místo termínu “text s akcentovanými znaky” bude dále používán termín “čeština”.
problém zobrazení češtiny vnitřně v Javě v podstatě neexistuje
vnitřně používá Unicode (dvoubajtový
char)
Java je ale provozována téměř výhradně na operačních systémech, které mají znaky téměř výhradně osmibitové
fonty, pomocí nichž se texty zobrazují
textové soubory, ve kterých jsou texty uloženy
problém – přizpůsobit šestnáctibitové znaky Javy osmibitovým znakům jejího okolí
podrobný rozbor viz přednáška z PPA1
Java přímo podporuje množství kódování, která mají v Core API zavedené zkratky
podle pokusů se někdy rozlišují a někdy nerozlišují velká a malá písmena zkratek
použijete-li nevyhovující zkratku kódování, bude vyhozena výjimka
UnsupportedEncodingException
kanonická jména čtyř nejběžnějších kódování:
ISO-8859-2– kódování dle mezinárodní normy (často v prostředí Unixů)známé též pod názvem ISO LATIN2
v Javě se občas vyskytne jako
ISO8859_2
windows-1250– proprietární kódování firmy Microsoftod
ISO-8859-2se liší jen v několika málo znacích (z akcentovaných znaků češtiny jsou to jen š, Š, ť, Ť, ž, Ž)
implicitní pro JDK pod Windows !
známé též pod názvem CP1250
v Javě se občas vyskytne jako
Cp1250
IBM852– kódování používané v konzolovém okénku Windows!občas je označováno jako DOS Latin2 nebo PC Latin 2
nezaměňovat s ISO LATIN2, které je zcela odlišné
v Javě se občas vyskytne jako
Cp852
UTF-8– jedno z nejrozšířenějších kódování pro Unicodev Javě se občas vyskytne jako
UTF8
jména identifikátorů – nejjednodušší problém – pouze zajistit, aby byl program správně přeložen
JDK pod Windows má implicitní kódování
windows-1250– překlad bez jakýchkoli problémů
texty výpisů – složitější
překlad bez problémů
výpis na konzoli s problémy – špatné akcenty – konzole je v
IBM852– řešení viz dále
public class CestinaIdentifikatory { public static void main(String[] args) { int pěknýČeskýČítač = 1; System.out.println("pěknýČeskýČítač = " + pěknýČeskýČítač); } }přeložení a spuštění:

v
.classsouboru je použitoUTF-8.classsoubory jsou plně přenositelné na jiné platformy
je-li zdrojový soubor v jiném než implicitním kódování, nastává již problém s překladem
tento soubor můžeme získat přenosem z jiné platformy (typicky z Linuxu) nebo (nevhodným) nastavením editoru
pro soubor
UTF8.java, který má jinak zcela stejný obsah jako předchozí soubor:public class UTF8 { public static void main(String[] args) { int pěknýČeskýČítač = 1; System.out.println("pěknýČeskýČítač = " + pěknýČeskýČítač); } }po pokusu o překlad dostaneme:

možným – ale neelegantním – řešením je promocí externího programu pro změnu kódování převést soubor do implicitního kódování
předchozí případ lze elegantně řešit přepínačem
encodingprogramujava.exerozpoznává všechna dříve uvedená kódování
překlad a spuštění souboru
UTF8.java(řešení špatného kódování konzole viz dále)
tento způsob je výhodný v případě, že zdrojový soubor ladíme, tj. editujeme
všechny nápisy v editoru zdrojového kódu vidíme v češtině
Caution
Záludnou chybou je uložení zdrojového souboru v
UTF-8 s BOM (Byte Order
Mark)
to často provede “editor o své vlastní vůli”
s BOM
javac.exenepočítá a překlad skončí chybouta je o to horší, že chybu při neznalosti principu BOM nelze odhalit, protože v editoru se BOM nezobrazuje
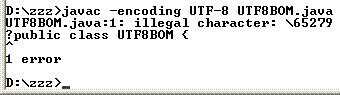
BOM je nutné se zbavit, což lze např pomocí editoru SciTe
zdrojové soubory v Javě nemají možnost (narozdíl od souborů XML) defifovat použité kódování
předáváme-li zdrojový soubor v nějakém kódování, záleží na zkušenostech příjemce, aby použité kódování správně rozpoznal a pak použil v přepínači
encodingsprávné rozpoznání není triviální záležitost
elegantním řešením problému je skutečnost, že každý akcentovaný znak může být ve zdrojovém souboru zapsán pomocí sekvence
\uXXXXXXXXje kódový bod znaku v Unicode, např. znak'ě'–'\u011b'
nahradíme-li takto ve zdrojovém souboru všechny akcentované znaky, dostaneme ASCII soubor
odstraníme trvale závislost na různém kódování
soubor je plně přenositelný a bez problémů přeložitelný
ovšem
převod znaků se velmi obtížně se provádí "ručně"
na převod použijeme program
native2ascii.exe, který je součástí JDKjeho parametr je
encodingmá zcela stejný význam jako ujavac.exerozdíl od předchozího způsobu je v tom, že
native2ascii.exepoužívá autor zdrojového kódu, který by měl znát použité kódovánínative2ascii.exevypisuje svůj výstup implicitně na konzolizapisujeme-li výstup do souboru, je vhodné (bezpečnější) použít pomocný soubor (zde
tmp.java) a ten pak přejmenovat na původní soubor
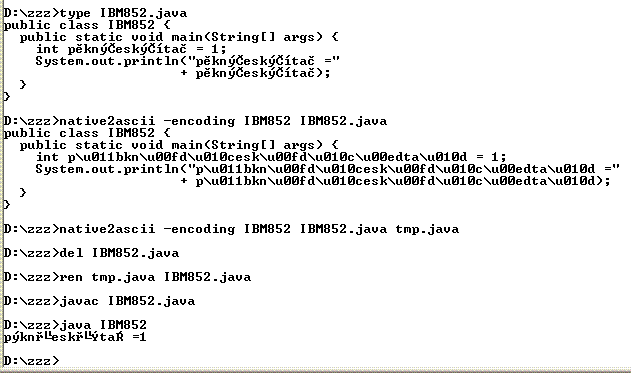
tento způsob provádíme na samém konci práce, když je zdrojový soubor odladěný a my jej archivujeme, či předáváme jinam
takto upravený zdrojový soubor se mimořádně špatně edituje
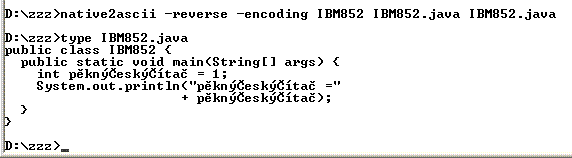
potřebujeme-li (rozsáhlejší editaci), použijeme
native2ascii.exes přepínačemreverseprovede převod sekvencí
'\uXXXX'na jejich akcentovanou podobu ve zvoleném kódovánív příkladu vznikající soubor
IBM852.javapřepíše původníIBM852.java(nepoužil se pomocný soubor)
Note
Spouštíme-li programy ze SciTe nebo Eclipse, s tímto problémem se
nesetkáme, protože ty již mají výstup v GUI Windows, tj. v iplicitním
kódování windows-1250.
konzolový výstup mají většinou jen zkušební nebo cvičné programy
stejný princip ale použijeme i při práci se soubory
základem veškerých změn kódování jsou třídy
InputStreamReaderaOutputStreamWriterpředstavují spojení mezi 8bitovými znaky operačního systému a 16bitovými znaky Javy
při čtení a při zápisu probíhá překódování znaků podle přednastaveného dekódování
ve Windows pro vstup i výstup přednastaveno kódování
windows-1250
pro změnu kódování použijeme pro obě třídy konstruktor
první parametr je instance
InputStreamneboOutputStream(tedy binární zpracování souboru!)druhý parametr je řetězec určující nové kódování
nově nastavený
OutputStreamWriterse pak použije např. jako parametrPrintWriter
import java.io.*;
public class NaKonzoli {
public static void main(String[] args) throws Exception {
OutputStreamWriter oswDef =
new OutputStreamWriter(System.out);
System.out.println("Implicitni kodovani konzole: "
+ oswDef.getEncoding());
/* IBM852 je výstupní kódování češtiny v DOSovém okénku */
OutputStreamWriter osw =
new OutputStreamWriter(System.out, "IBM852");
System.out.println("Nastavene kodovani konzole: "
+ osw.getEncoding());
PrintWriter p = new PrintWriter(osw);
p.print("Příšerně žluťoučký kůň úpěl ďábelské ódy.\n");
p.print("áčďéěíňóřšťúůýž\n");
p.print("PŘÍŠERNĚ ŽLUŤOUČKÝ KŮŇ ÚPĚL ĎÁBELSKÉ ÓDY.\n");
p.print("ÁČĎÉĚÍŇÓŘŠŤÚŮÝŽ\n");
p.flush();
}
}překlad a spuštění

používají se zde “stará” označení kódování (
Cp1250,Cp852)
princip je velmi podobný výstupu na konzoli
zde jsou ukázány dvě možnosti vstupu
pomocí
InputStreamReader– tento způsob se pak použije pro vstup ze souborůpomocí
Scanner– běžný způsob načítání z klávesnice
import java.io.*;
import java.util.*;
public class IOKonzole {
public static void main(String[] args) throws Exception {
OutputStreamWriter osw =
new OutputStreamWriter(System.out, "IBM852");
PrintWriter p = new PrintWriter(osw);
InputStreamReader isr =
new InputStreamReader(System.in, "IBM852");
BufferedReader ib = new BufferedReader(isr);
Scanner sc = new Scanner(System.in, "IBM852");
p.print("Zadej akcentované znaky: ");
p.flush();
String s = sc.nextLine();
p.print("Zadal jsi: " + s + "\n");
p.flush();
p.print("Zadej další akcentované znaky: ");
p.flush();
s = ib.readLine();
p.print("Zadal jsi: " + s + "\n");
p.flush();
}
}
situace prakticky stejná, jako s češtinou z konzole
třída
Readerčte bajty, které konvertuje na znaky podle implicitního kódovánítotéž platí pro třídu
Writer– zapisuje 16bitové znaky, ale v souboru se objeví jejich 8bitová náhrada
znamená to, že
ReaderaWriterlze správně použít jen pro implicitní kódováníto lze zjistit ze systémové vlastnosti
file.encodingpříkazemSystem.getProperty("file.encoding")
zpracování pomocí jiného kódování je stejné jako u konzole – třídy
InputStreamReaderaOutputStreamWriternikdy se nesnažíme o změnu
file.encoding!!!
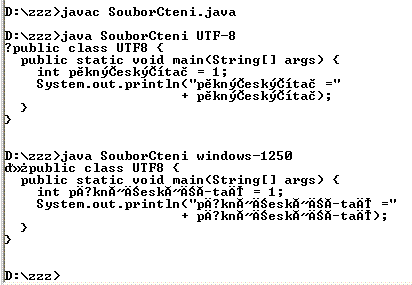
Ukázka, jak načíst soubor v jiném kódování než
windows-1250. Zkratka požadovaného kódování se zadá z
příkazové řádky a soubor se kontrolně opíše na obrazovku způsobem známým z
předchozí části. Zadáme-li z příkazové řádky UTF-8, vypíše se
správný text. Zadáme-li např. windows-1250, dostaneme
částečně nesmyslný výpis.
import java.io.*;
public class SouborCteni {
public static void main(String[] args) throws Exception {
OutputStreamWriter osw =
new OutputStreamWriter(System.out, "IBM852");
PrintWriter p = new PrintWriter(osw);
String kodovani = args[0];
FileInputStream fis =
new FileInputStream("vstup.utf8");
InputStreamReader isr =
new InputStreamReader(fis, kodovani);
BufferedReader br = new BufferedReader(isr);
String radka;
while ((radka = br.readLine()) != null) {
p.println(radka);
p.flush();
}
fis.close();
}
}
Totéž lze použít i pro výstupní soubor. Zde máme možnost vytvořit
více souborů se stejným obsahem, ale jiným kódováním. Typ kódování se zadá
z příkazové řádky a je to současně i přípona souboru se jménem
vystup. Metoda toUpperCase() třídy
String převádí zcela správně akcentované znaky, bez ohledu na
jejich kódování. Je to tím, že řetězec kun (nebo
akcenty) je v Javě 16bitový Unicode – nemá s výstupním
kódováním nic společného.
import java.io.*;
public class SouborZapis {
public static void main(String[] args) throws Exception {
String kodovani = args[0];
String jmenoSouboru = "vystup." + kodovani;
FileOutputStream fos = new FileOutputStream(jmenoSouboru);
OutputStreamWriter osw =
new OutputStreamWriter(fos, kodovani);
PrintWriter p = new PrintWriter(osw);
String kun = "Příšerně žluťoučký kůň úpěl ďábelské ódy";
String akcenty = "áčďéěíňóřšťúůýž";
p.println(kun);
p.println(akcenty);
p.println(kun.toUpperCase());
p.println(akcenty.toUpperCase());
p.close();
}
}
v rámci programu potřebujeme získat z řetězce znaky v daném kódování
metoda
byte[] getBytes(String kodovani)třídyStringpro řetězec vrátí pole bajtů ve zvoleném kódování
opačný postup je, máme-li pole bajtů v určitém kódování a potřebujeme z něj získat řetězec
konstruktor
String(byte[] bytes, String kodovani)
Jak lze snadno zjistit kódy jednotlivých znaků pro různá kódování.
public class PrevodStringu {
public static String byteNaHexa(byte[] b) {
String s = " ";
for (int i = 0; i < b.length; i++) {
int j = (b[i] < 0) ? 256 + b[i] : b[i];
s = s + s.format("%02x ", j);
}
return s;
}
public static void main(String[] args) throws Exception {
String test = "áčďéěíňóřšťúůýž";
String[] kodovani = {"windows-1250", "ISO-8859-2 ",
"IBM852 ", "UTF-8 ",
"UTF-16BE ", "UTF-16LE ",
"UTF-16 "};
for (int i = 0; i < kodovani.length; i++) {
byte[] b = test.getBytes(kodovani[i].trim());
System.out.println(kodovani[i] + ":" + byteNaHexa(b));
}
}
}windows-1250: e1 e8 ef e9 ec ed f2 f3 f8 9a 9d fa f9 fd 9e ISO-8859-2 : e1 e8 ef e9 ec ed f2 f3 f8 b9 bb fa f9 fd be IBM852 : a0 9f d4 82 d8 a1 e5 a2 fd e7 9c a3 85 ec a7 UTF-8 : c3 a1 c4 8d c4 8f c3 a9 c4 9b c3 ad c5 88 c3 b3 c5 99 c5 a1 c5 a5 c3 ba c5 af c3 bd c5 be UTF-16BE : 00 e1 01 0d 01 0f 00 e9 01 1b 00 ed 01 48 00 f3 01 59 01 61 01 65 00 fa 01 6f 00 fd 01 7e UTF-16LE : e1 00 0d 01 0f 01 e9 00 1b 01 ed 00 48 01 f3 00 59 01 61 01 65 01 fa 00 6f 01 fd 00 7e 01 UTF-16 : fe ff 00 e1 01 0d 01 0f 00 e9 01 1b 00 ed 01 48 00 f3 01 59 01 61 01 65 00 fa 01 6f 00 fd 01 7e
nejdůležitější třída pro práci s národním prostředím
je z balíku
java.util
ovlivňuje činnost mnoha dalších tříd
lze vytvořit její instanci, která je pak dalšími třídami používána
problém změny národního prostředí se tak redukuje na změnu pomocí jedné řádky kódu
uschovává informace o jazyku a o oblasti (zemi, státu)
statická metoda
Locale.getDefault()vrací objekt, který popisuje aktuální nastavení pro právě platnou instanci JVMnastavení se shoduje s nastavením, které lze změnit v operačním systému
pro Windows XP je to ve Start/Control Panel/Regional Settings
dále bude používán pojem lokalita = kombinace jazyka a země
Výpis hodnot pro přednastavenou lokalitu.
import java.util.*;
import java.io.*;
public class MojeLocale {
public static void main(String[] args) throws Exception {
Locale d = Locale.getDefault();
System.out.println("Země : " + d.getCountry());
System.out.println("Jazyk: " + d.getLanguage());
System.out.println("Země : " + d.getDisplayCountry());
System.out.println("Jazyk: " + d.getDisplayLanguage());
System.out.println("ISO země : " + d.getISO3Country());
System.out.println("ISO jazyk: " + d.getISO3Language());
}
}vypíše pro Control Panel/Regional Setting/Czech:
Země : CZ Jazyk: cs Země : Česká republika Jazyk: čeština ISO země : CZE ISO jazyk: ces
metoda
void setDefault(Locale newLocale)dokáže pro konkrétní instanci JVM (ne pro operační systém!) změnit lokalitu
instanci třídy
Localedostaneme pomocíLocale(String jazyk, String zeme)je možné pracovat s více lokalitami najednou
příklady použití konstruktoru a zkratek jazyků a zemí
czLocale = new Locale("cs", "CZ"); skLocale = new Locale("sk", "SK"); usLocale = new Locale("en", "US"); gbLocale = new Locale("en", "GB");objekty
Localejsou pouze identifikátory, které samy nejsou schopny žádné činnostiposkytují se jiným třídám jako parametry jejich "výkonných" metod
tyto metody ale nemusejí podporovat všechny možné kombinace jazyků a zemí
podporované lokality lze u každé třídy, která je s nimi schopna pracovat, zjistit voláním statické metody
getAvailableLocales()vrátí pole všech podporovaných
Locale, např.:Locale[] l = DateFormat.getAvailableLocales();
podle pokusů patří lokality "cs_CZ" a "sk_SK" vždy mezi podporované
před JDK 1.5 málo přehledné použití několika různých tříd
NumberFormatpro čísla, měnyDecimalFormatpro speciální formát celých a reálných číselDateFormataSimpleDateFormatpro data a časy
od JDK 1.5 lze použít metodu
format()ze třídPrintStreamaStringnedokáže ale předchozí třídy plně nahradit
Note
Používáme jen tehdy, když nám nestačí možnosti
System.out.println().
jasná inspirace možnostmi jazyka C
možnost volit šířku výpisu, zarovnávání doprava či doleva, nevýznamové mezery a množství dalších věcí
vyčerpávající informace i s příklady viz
java.util.Formatter
základní statická metoda
String.format(parametr)poskytne řetězec, který se dá dále zpracovat (poslat na výstup – stream, soubor, GUI, ...)
stejná metoda je ve třídě
PrintStream, tj.System.out.format()vyřešeno přenositelně odřádkování pomocí
%n, např.:String.format("nova radka%n");základní princip je formátovací řetězec jako první parametr a pak jednotlivé položky jako další parametry
základní pravidla
ve formátovacím řetězci jsou za znakem
%formátovací znaky
kolik je znaků
%, tolik musí být dalších parametrů (s výjimkou%n)
String.format("i = %d, j = %d%n", i, j);
používá se
%d, např. proint i = -1234;String.format("i = %d%n", i); // i = -1234počet míst lze stanovit, pak se doplňují mezery zleva, tj. zarovnání doprava, např.:
String.format("i = %7d%n", i); // i = -1234počet míst lze stanovit a zarovnat doleva (zbylé místo se doplní mezerami), např.:
String.format("i = %-7dahoj%n", i); // i = -1234 ahojlze vynutit výpis i + znaménka, např. pro
int i = 1234;String.format("i = %+7d%n", i); // i = +1234vynutí se výpis nevýznamových nul, např.:
String.format("i = %07d%n", i); // i = -001234
osmičková soustava, např. pro
int j = 30;String.format("j = %o%n", j); // j = 36šestnáctková soustava, např. pro
int j = 30;String.format("j = %X%n", j); // j = 1Epočet míst lze určit, např.:
String.format("j = %3X%n", j); // j = 1Elze vynutit nevýznamové nuly, např. pro:
int j = 10;String.format("j = %02X%n", j); // j = 0A
používá se
%c, např. prochar c = 'a';String.format("c = %c%n", c); // c = alze použít přetypování a lze vypsat více proměnných najednou
String.format("Znak %c ma ASCII hodnotu: %d%n", c, (int) c);// Znak a ma ASCII hodnotu: 97
výpis jako běžné reálné číslo
%f, např. prodouble d = 1234.567;String.format("d = %f%n", d); // d = 1234,567000Note
Desetinný oddělovač je závislý na lokalitě – pro ČR je to čárka, nikoliv tečka.
výpis ve vědeckotechnické notaci
%g, např. prodouble d = 1234.567;String.format("d = %g%n", d); // d = 1.234567e+03Note
Desetinný oddělovač je tečka.
lze nastavit počet míst celkem (10) a počet míst za desetinným oddělovačem (1), číslo bude zaokrouhleno
String.format("d = %10.1f%n", d); // d = 1234,6lze použít zarovnání doleva, výpis nevýznamových nul, oddělovač řádů apod. stejně, jako u celého čísla
používá se
%s, např. proString s = "Ahoj lidi";String.format("s = %s%n", s); // s = Ahoj lidiřetězec lze vypsat velkými písmeny
String.format("s = %S%n", s); // s = AHOJ LIDIlze stanovit šířku výpisu, výpis bude zarovnán doprava
String.format("s = |%11s|%n", s); // s = | Ahoj lidi|výpis lze zarovnat i doleva
String.format("s = |%-11s|%n", s); // s = |Ahoj lidi |
format()využívá přednastavenou lokalituvhodnější je však danou lokalitu zadat pro každé použití
String.format(lokalita, formátovací_řetězec, tisknuté_parametry)
u čísel se v národních zvyklostech mění desetinný oddělovač a oddělovač řádů
jejich používání se ve format() vynutí pomocí znaku “
,” (čárka) bezprostředně za znakem “%”
Ukázka používaných oddělovačů v různých lokalitách. Průzkum typu
oddělovače řádů v české lokalitě. Formátovací řetězec "%,.2f
\t%s%n" znamená:
,– tiskni oddělovač řádů.2– tiskni na dvě desetinná místa se zaokrouhlenímf– tiskni reálné číslo\t– tiskni mezeru a tabulátor%s– tiskni řetězec (zde název lokality)%n– tiskni odřádkovávací znaky dle konvencí platformy
Výpis znaku “ě” (kódový bod \u011b) v
dalším tisku je proto, aby byl zřejmý rozsah a uložení bajtů.
import java.util.*;
public class CislaLocale {
public static void main(String[] args) throws Exception {
double d = 1234567.894;
Locale[] lo = { new Locale("cs", "CZ"),
new Locale("sk", "SK"),
new Locale("en", "US"),
new Locale("de", "DE") };
for (int i = 0; i < lo.length; i++) {
System.out.format(lo[i], "%,.2f \t%s%n", d,
lo[i].getDisplayName());
}
double d1 = 1234.5;
String s = String.format(lo[0], "ě %,.2f", d1);
byte[] b = s.getBytes("UTF-16BE");
for (int i = 0; i < b.length; i++) {
int j = (b[i] < 0) ? 256 + b[i] : b[i];
System.out.format("%02x ", j);
}
}
}vypíše:
1 234 567,89 čeština (Česká republika) 1 234 567,89 Slovak (Slovakia) 1,234,567.89 English (United States) 1.234.567,89 German (Germany) 01 1b 00 20 00 31 00 a0 00 32 00 33 00 34 00 2c 00 35 00 30
v české typografii je oddělovač řádů pevná mezera šířky čtvrt čtverčíku (“čtverčík” je typografický termín)
Java tento znak nepoužívá (měl by kódový bod
\u202F[narrow no-break space])místo něj používá pevnou mezeru (kódový bod
\u00A0[no-break space])není-li tento znak k dispozici v používaném fontu, zobrazí se nesmyslný znak, např. při výpisu na konzoli:
1á234á567,89
budou-li ale takto formátovaná čísla na vstupu, bude jako oddělovač řádů velmi pravděpodobně použita normální mezera (kódový bod
\u0020)to je důvod, proč se prakticky téměř nikdy nepodaří takto formátovaná čísla načíst
Ukázka načtení reálného čísla. Použijeme známý
Scanner s nastavenou lokalitou. V české lokalitě zadáme
číslo bez oddělovače řádů, protože znak \u00A0 se zadává
z klávesnice špatně a znak mezery by byl interpretován jako konec
čísla.
import java.util.*;
public class CislaLocaleCteni {
public static void main(String[] args) throws Exception {
Locale[] lo = { new Locale("cs", "CZ"),
new Locale("en", "US") };
Scanner sc = new Scanner(System.in).useLocale(lo[1]);
System.out.print("Zadej realne cislo (1,234,567.89): " );
double d = sc.nextDouble();
System.out.println(d);
sc = new Scanner(System.in).useLocale(lo[0]);
System.out.print("Zadej realne cislo (1234567,89): " );
d = sc.nextDouble();
System.out.println(d);
}
}vypíše:
Zadej realne cislo (1,234,567.89): 98,765.432 98765.432 Zadej realne cislo (1234567,89): 98765,432 98765.432
Number Format Pattern Syntax na: http://java.sun.com/docs/books/tutorial/i18n/format/decimalFormat.html
zde je vhodné použít třídu
java.text.NumberFormatjejí instanci vhodnou pro výpis měny získáme tovární metodou
getCurrencyInstance()u instance
NumberFormatpak využíváme metoduformat(), která je zcela jiná než dříve popisovanýString.format()při výpisu se bere ohled na to, kolik desetinných míst se při výpisu měny používá
např. koruna se skládá ze sta haléřů – výpis je na dvě desetinná místa
Výpis měnových hodnot. Znak $ je uveden (dle
amerických zvyklostí) automaticky před číslem. Symbol měny je možné
též získat ze třídy Currency a pak použít známý
String.format().
import java.util.*;
import java.text.*;
public class MenaLocale {
public static void main(String[] args) throws Exception {
NumberFormat nf;
double d = 1234567.894;
Locale[] lo = { new Locale("cs", "CZ"),
new Locale("sk", "SK"),
new Locale("en", "US"),
new Locale("de", "DE") };
for (int i = 0; i < lo.length; i++) {
nf = NumberFormat.getCurrencyInstance(lo[i]);
String s = nf.format(d);
System.out.println(s + "\t" + lo[i].getDisplayName());
}
Currency cur = Currency.getInstance(lo[0]);
String symbol = cur.getSymbol();
System.out.format(lo[0], "%,.2f %s %n", d, symbol);
}
}vypíše:
1 234 567,89 Kč čeština (Česká republika) 1 234 567,89 Sk Slovak (Slovakia) $1,234,567.89 English (United States) 1.234.567,89 € German (Germany) 1 234 567,89 Kč
konvence v zobrazování datumu a času jsou v různých lokalitách velmi odlišné
třída
java.text.DateFormatspolehlivě funguje pro různé lokality
Ukázka různých výpisů datumu.
import java.util.*;
import java.text.*;
public class DatumLocale {
public static void main(String[] args) throws Exception {
DateFormat df;
Date d = new Date();
Locale[] lo = { new Locale("cs", "CZ"),
new Locale("sv", "SE"),
new Locale("en", "US"),
new Locale("de", "DE") };
for (int i = 0; i < lo.length; i++) {
df = DateFormat.getDateInstance(DateFormat.DEFAULT, lo[i]);
String s = df.format(d);
System.out.println(s + "\t" + lo[i].getDisplayName());
}
}
}vypíše:
4.3.2007 čeština (Česká republika) 2007-mar-04 Swedish (Sweden) Mar 4, 2007 English (United States) 04.03.2007 German (Germany)
metoda
getDateInstance()má dva parametry – první určuje množství vypisované informace (mod výpisu)
platí stejná pravidla, pouze se instance třídy
DateFormatzíská metodougetTimeInstance()opět má jako první parametr konstanty
DateFormat–DEFAULT,SHORT,MEDIUM,LONG,FULLprakticky použitelné jsou:
DEFAULT– 19:53:20SHORT– 19:53
dává možnost vytvořit si vlastní formát datumu a času
nastavení lokality však tento výpis ovlivňuje velmi málo
prakticky jen výpis názvů měsíců a názvů dnů slovem
formátovací řetězec je vždy uvozen
%tza nímž následuje další písmenoto může určovat buď jeden údaj, např.
%tBplné jméno měsíce,%tAplné jméno dne,%tHhodina ve 24hodinovém cyklu atd.může být závislý na lokalitě
nebo určuje skupinu údajů, např.
%tTvýpis hodina:minuta:sekunda,%tFvýpis rok-měsíc-dennení závislý na lokalitě
všechny možnosti jsou přehledně popsány v
java.util.Formattervelmi zajímavé je, že skutečným parametrem může být buď objekt třídy
Calendar(nebo potomků –GregorianCalendar) nebo proměnná typulong, ve které je počet milisekund od 1.1.1970
Výpis časových údajů pomocí format().
import java.util.*;
import java.text.*;
public class DatumLocaleFormat {
public static void main(String[] args) throws Exception {
Calendar c = Calendar.getInstance();
Date d = c.getTime();
long l = d.getTime();
Locale[] lo = { new Locale("cs", "CZ"),
new Locale("sv", "SE"),
new Locale("en", "US"),
new Locale("de", "DE") };
for (int i = 0; i < lo.length; i++) {
System.out.format(lo[i], "%tB %tA %tF \t %s %n",
l, c, l, lo[i].getDisplayName());
}
}
}vypíše:
březen Neděle 2007-03-04 čeština (Česká republika) mars söndag 2007-03-04 Swedish (Sweden) March Sunday 2007-03-04 English (United States) März Sonntag 2007-03-04 German (Germany)
při porovnávání jen na rovnost pomocí
String.equals()žádné problémy nenastanouchceme-li např. řadit řetězce podle abecedy a k tomu využít metodu
String.compareTo(), pak české znaky v řetězci způsobí potížetato metoda vrací číslo menší nebo větší než nula v případě nerovnosti porovnávaných řetězců
jakmile je v řetězci akcentovaný znak, pak svým kódováním zcela “vybočuje z řady” neakcentovaných znaků
např. v české abecedě je posloupnost B, C, Č, D – kódové body těchto znaků jsou
\u0042,\u0043,\u010C,\u0044
pro tento případ máme třídu
java.text.Collatorspolupracující sLocalev Java Core API v dokumentaci k
Collatorje čeština se svým třífázovým řazením uváděna jako příklad“For example, in Czech, "e" and "f" are considered primary differences, while "e" and "ě" are secondary differences, "e" and "E" are tertiary differences...”
prakticky to znamená, že pro porovnávání řetězců v češtině je již vše připraveno
řazení v češtině je definováno normou
řazení probíhá ve třech fázích
v první fázi se nerozlišuje velikost znaků a také se nerozlišují některé akcenty
znaky s takzvanou “primární řadicí platností” jsou:
a b c č d e f g h ch i j k l m n o p q r ř s š t u v w x y z ž
ve druhé fázi se pro stejné řetězce z první fáze berou v úvahu znaky se “sekundární řadicí platností”:
á ď é ě í ň ó ť ú ů ýkteré se v první fázi řadily jako:
a d e e i n o t u u yjsou-li dvě slova až na akcenty stejná, pak se slovo bez akcentů dává na první místo a slovo s akcenty na druhé
ve třetí fázi se navíc rozlišuje i velikost znaků
nejprve se řadí slova s malými písmeny a pak slova s velkými písmeny
seřadíme-li příklady uváděné v normě programem v Javě, dostaneme výsledek přesně podle normy
stačí jen zajistit, aby
Collatorpoužíval správnou lokalituprotože se jedná o absolutní řazení, je možné řadit nejen pole řetězců, ale i řetězce v odpovídajících kolekcích
Ukázka abecedního řazení podle normy – vstupní pole řetězců je právě v opačném pořadí.
import java.util.*;
import java.text.*;
import java.io.*;
public class Razeni {
public static void main(String[] args) throws Exception {
String[] ret = { "nový věk",
"Nový Svět", "Nový svět",
"nový Svět", "nový svět",
"Nový Svet", "Nový svet" ,
"abc traktoristy",
"ABC nástrojaře", "abc nástrojaře",
"ABC kováře", "ABC klempíře",
"abc frézaře", "ABC",
"Abc", "abc", "A", "a" };
Arrays.sort(ret, new CeskyAbecedniComparator());
for (int i = 0; i < ret.length; i++) {
System.out.println(ret[i]);
}
}
}
class CeskyAbecedniComparator implements Comparator<String> {
private Collator ceskyCol = Collator.getInstance(
new Locale("cs", "CZ"));
public int compare(String s1, String s2) {
return ceskyCol.compare(s1, s2);
}
}vypíše:
a A abc Abc ABC abc frézaře ABC klempíře ABC kováře abc nástrojaře ABC nástrojaře abc traktoristy Nový svet Nový Svet nový svět nový Svět Nový svět Nový Svět nový věk
detekovat jednotlivá slova je při práci s textem nutnost
zlom řádek
zvýraznění (výběr) slov “dvojklikem”, ...
pokud slova detekujeme “ručně”, používáme zásadně konstrukci
if (Character.isLetter(ch)) {případně ještě metody
isDigit(),isLetterOrDigit(),isLowerCase()aisUpperCase()
na automatickou detekci slov, vět a případně i možných zlomů řádek existuje
java.text.BreakIteratorpodobně jako u datumů a časů získáváme instanci
BreakIteratorpomocí statických metod:getCharacterInstance()– detekuje hranice znaků (znak ch)getWordInstance()– detekuje hranice slovgetSentenceInstance()– detekuje hranice větgetLineInstance()– detekuje místa možného zlomu řádek
všechny fungují pro přednastavenou lokalitu
pro jinou lokalitu použijeme jejich přetížené verze s parametrem typu
Locale
instanci je nutné nejdříve nastavit zkoumaný text metodou
void setText(String text)BreakIteratorpoužívá vlastní ukazatel na hranice slovdá se posouvat doprava –
next()a doleva –previous()dá se nastavit na začátek –
first()a na konec –last()další metody vrací hraniční indexy od zadaného ofsetu –
following(int offset)apreceding(int offset)všechny vrací
int– index do řetězce
BreakIteratorza samostatné úseky považuje i mezery a interpunkcije třeba použít metodu
Character.isLetter()pro znak na dané hranici
procházíme-li postupně celý řetězec, použije se
BreakIterator.DONEpro ukončení cyklu
Ukázka, jak lze vyseparovat jednotlivá česká slova z textu.
import java.io.*;
import java.text.*;
public class BreakIterator1 {
public static void main(String[] args) throws Exception {
String veta = "Příšerně 'žluťoučký' kůň úpěl ďábelské " +
"ódy, které se nedaly poslouchat.";
BreakIterator wbi = BreakIterator.getWordInstance();
wbi.setText(veta);
int zac = wbi.first();
int kon = wbi.next();
while (kon != BreakIterator.DONE) {
String slovo = veta.substring(zac, kon);
if (Character.isLetter(slovo.charAt(0))) {
System.out.println(slovo);
}
zac = kon;
kon = wbi.next();
}
}
}vypíše:
Příšerně žluťoučký kůň úpěl ďábelské ódy které se nedaly poslouchat
Na i18n se používají se
.propertiessouboryPříklad vše ozřejmí
Nejprve se podívejme na program, který i18n potřebuje
public class NotI18N { static public void main(String[] args) { System.out.println("Hello."); System.out.println("How are you?"); System.out.println("Goodbye."); } }
Nejjednodušíí, nejelegantnější a nejsnazší je řešení pomocí třídy
ResourceBundlehttp://java.sun.com/docs/books/tutorial/i18n/resbundle/propfile.html
Připravíme několik textových
.propertiessouborů podle jasně dané jmenné konvence:Soubor
MessagesBundle_de_DE.properties:# FOR GERMAN ... tohle je komentář ... následují páry klíč = hodnota greetings = Hallo. farewell = Tschüß. inquiry = Wie geht's?
Soubor
MessagesBundle_fr_FR.properties:greetings = Bonjour. farewell = Au revoir. inquiry = Comment allez-vous?
A nezapomeneme na defaultní
MessagesBundle.propertiesgreetings = Hello. farewell = Goodbye. inquiry = How are you?
Upravíme kód tak, že použijeme třídy
LocaleaResourceBundleimport java.util.*; public class I18NSample { static public void main(String[] args) { String language, country; if (args.length != 2) { language = new String("en"); country = new String("US"); } else { language = new String(args[0]); country = new String(args[1]); } Locale currentLocale = new Locale(language, country); ResourceBundle messages = ResourceBundle.getBundle("MessagesBundle",currentLocale); System.out.println(messages.getString("greetings")); System.out.println(messages.getString("inquiry")); System.out.println(messages.getString("farewell")); } }Výstup programu je pak (včetne příkazu, kterým se spustí):
% java I18NSample fr FR Bonjour. Comment allez-vous? Au revoir.
Je vidět, že program tiskne text ze spravneho
.propertiessouboruPokud pouzijete
Locale, ke keterému neexistuje.propertiessoubor (například kombinacefraCA)použije se defaultníMessagesBundle.propertiesMůžete specifikovat i platformu:
Locale currentLocale = new Locale("fr", "CA", "UNIX");
http://java.sun.com/docs/books/tutorial/i18n/format/messageFormat.html
Někdy texty obsahují prěměnlivé ůdaje například:
The current balance of account #34-98-222 is $2,745.72.
Delete all files older than 120 days.
Naivní řešení ...
ResourceBundle msgBundle; ... String message = msgBundle.getString("deleteolder" + numDays.toString() // to je těch 120 + msgBundle.getString("days"));... fungule pro angličtinu, ale už nemusí fungovat pro např. němčinu, kde po číslovce může být nejen slovíčko "Tag", ale také sloveso
Řešením je použití třídy
MessageFormata její metodyformatspolu s drobnou úpravou.propertiessouboru# .properties soubor deleteOrder = Delete all files older than {0} days.ResourceBundle messages = ResourceBundle.getBundle("MessageBundle",currentLocale); MessageFormat formatter = new MessageFormat(""); // pattern zatím neuvažujeme formatter.setLocale(currentLocale); formatter.applyPattern(messages.getString("deleteOrder")); Object[] argumentyZpravy = {new Integer(120)}; String output = formatter.format(argumentyZpravy); System.out.println(output);Složitejší příklad z Java Tutorialu:

# .properties soubor template = At {2,time,short} on {2,date,long}, we detected \ {1,number,integer} spaceships on the planet {0}. planet = MarsObject[] argumentyZpravy = { messages.getString("planet"), new Integer(7), new Date() }; String output = formatter.format(argumentyZpravy);Na http://java.sun.com/docs/books/tutorial/i18n/format/choiceFormat.html je ukázáno, jak si poradit s variantami:
Žádné soubory nenalezeny
Nalezen 1 soubor
Nalezeny 2 soubory
Nalezeno 5 souborů
Formátování může být důmyslně řízeno -- dataily na http://java.sun.com/javase/6/docs/api/java/text/MessageFormat.html
Za třídou
ResourceBundlebyl textový soubor. Za třídouListResourceBundleje třída.http://java.sun.com/docs/books/tutorial/i18n/resbundle/list.html
Uvažujme dvě Locale
StatsBundle_fr_FR.class
StatsBundle_ja_JP.class
Pro Japonsko pak třída vypadá takto:
import java.util.*; public class StatsBundle_ja_JP extends ListResourceBundle { public Object[][] getContents() { // jediná metoda - vrací 2D pole return contents; } private Object[][] contents = { // zde je definováno 2D pole { "GDP", new Integer(21300) }, // explicitní převod int na Integer { "Population", new Integer(125449703) }, { "Literacy", new Double(0.99) }, }; }
Použití v programu:
Locale currentLocale = new Locale("ja","JP"); // neboLocale.getDefault()ResourceBundle stats = ResourceBundle.getBundle("StatsBundle",currentLocale); Integer gdp = (Integer)stats.getObject("GDP"); System.out.println("GDP = " + gdp.toString()); Integer pop = (Integer)stats.getObject("Population"); System.out.println("Population = " + pop.toString()); Double lit = (Double)stats.getObject("Literacy"); System.out.println("Literacy = " + lit.toString());