

V přírodě biologičtí jedinci jedné populace mezi sebou soutěží o přežití a možnost reprodukce na základě toho, jak dobře jsou přizpůsobeni prostředí. V průběhu mnoha generací se struktura dané populace vyvíjí na základě Darwinovy teorie o přirozeném výběru a přežívání jen těch jedinců, kteří mají největší sílu (schopnost přežít; v anglosaských zemích se pro tuto hodnotu používá termín fitness ).
Evoluční algoritmy se snaží využít modelů evolučních procesů, aby tak nalezly řešení náročných a rozsáhlých úloh. Veškeré takové modely mají několik společných rysů:
1) pracují zároveň s celou skupinou (množinou) možných řešení zadaného problému místo hledání jednotlivého řešení;
2) vygenerovaná řešení postupně vylepšují zařazováním nových řešení, získaných kombinací původních;
3) kombinace řešení jsou následovány náhodnými změnami a vyřazováním nevýhodných řešení.
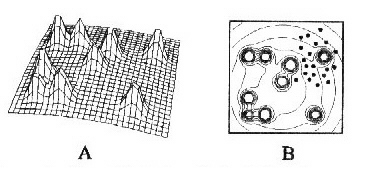
Obr.1: Znázornění povrchu fitness (A), který vyjadřuje závislost síly (fitness) jedinců na složení jejich genotypu. V tomto jednoduchém případě se jedná o organismus s dvojgenovým chromozómem, přičemž jeho složkami jsou reálná čísla. Konturový graf (B) odpovídá povrchu fitness, oblak bodů znázorňuje populaci jedinců.

Základní myšlenkou genetických algoritmů je snaha napodobit vývoj a učení nějakého živočišného druhu a takto vzniklý algoritmus použít při řešení úloh, které se vyskytují ve složitém, případně i měnícím se prostředí, kde programátor není schopen dopředu nadefinovat všechny vzniklé případy a správné reakce na ně.
Snahou napodobit přírodu vznikly dva typy přístupů. Prvním jsou umělé neuronové sítě napodobující činnost mozku a používané v praxi pro předpovědi nebo pro klasifikaci objektů na základě předem daných vstupních informacích se známými odpověďmi. Druhým přístupem jsou genetické algoritmy používané hlavně pro řešení problémů učení a adaptace.V přírodě a tedy i v genetických algoritmech platí, že kvalitnější jedinci se častěji rozmnožují a také déle přežívají, proto zanechávají více potomků, kteří nesou dál část jejich genetické informace. Přesto je tento výběr ovlivněn náhodou, neboť se i kvalitní řešení vybírají k dalšímu přežití sice úměrně své kvalitě, avšak náhodně. V informatice pro tento tzv. kvazináhodný výběr podle kvality používáme zařízení nazývané "ruleta".
Situaci, kdy se většina jedinců natolik zkříží, že by další křížení produkovalo stejné jedince a tudíž nemělo smysl, brání mutace. Mutace také nabízejí možnost adaptovat populaci na měnící se prostředí, ale musí se provádět jen u malého procenta populace, protože často už dobré řešení spíše pokazí.
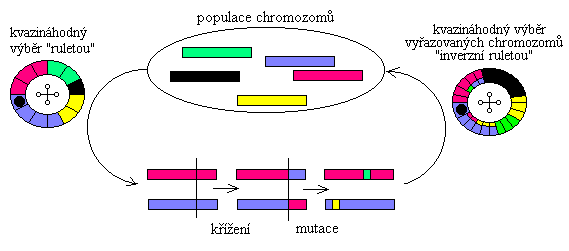
Obr.2 : Z populace se kvazináhodně vyberou dva chromozómy, které si křížením vymění část řetězců. Výsledné chromozómy se pak ještě podrobí mutaci, která překlopí náhodně zvolený bit. Tato dvojice se vrací do populace, kde vytěsní dvojici kvazináhodně vybraných chromozómů s malou silou.
Jedinec řešení (chromozóm) je nejčastěji implentován lineární posloupností symbolů, např. bitovým řetězcem. Každý chromozóm je ohodnocen funkcí, která mu přiřadí tzv. sílu, vyjádřenou kladným reálným číslem. Čím má chromozóm větší sílu, tím je kvalitnější.
Implementace genetického algoritmu v pseudoPascalu:

Velké uplatnění nacházejí genetické algoritmy při vytváření rozvrhů práce pro stroje v továrnách, v teorii her, v managementu, pro řešení optimalizačních problémů multimodálních funkcí, při řízení robotů, v rozpoznávacích systémech a v úlohách umělého života.
Genetické algoritmy překvapivě dobře fungují při řešení problémů, kde téměř všechny ostatní algoritmy selhávají, např. pro NP-úplné problémy, tj. kde výpočetní čas je exponenciálně nebo faktoriálně závislý na počtu proměnných. Nemá však smysl je používat u relativně jednoduchých optimalizovaných funkcí nebo u funkcí, pro které existují specializované algoritmy.

Na přelomu 80. a 90.let americký informatik John Koza ze Stanfordské univerzity navrhl originální modifikaci genetického algoritmu, kterou nazval genetické programování. Při tomto přístupu je původní reprezentace chromozómů znakovými řetězci nahrazena složitějšími funkcemi. V nejjednodušší verzi genetického programování se funkce rovnají výrazům obsahujícím proměnné, konstanty, základní aritmetické operace a elementární funkce.
K tomu, aby genetické programování bylo schopné řešit také složitější algoritmické úlohy, musí obsahovat vhodné příkazy pro zápis do paměti, načítání z paměti a pro opakování příkazu. Pokud genetické programování rozšíříme o tyto tři příkazy, potom je tzv. Turingovsky úplné. To tedy znamená, že je schopné realizovat každý algoritmus, který je realizovatelný na Turingově počítači.
Příklad použití genetického programování.
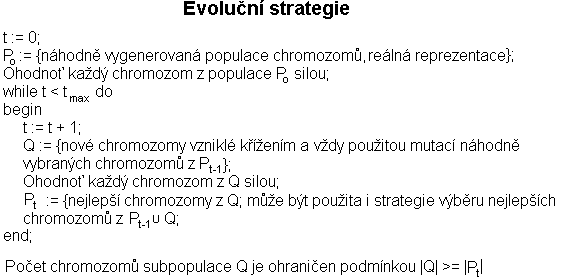
Když kolem roku 1963 začali – tehdy ještě studenti – Hans-Paul Schwefel a Ingo Rechenberg na Technické univerzitě v Berlíně s napodobováním vývoje v přírodě, byli přesvědčeni, že jejich metoda nejlépe napodobuje evoluci v živé přírodě. Proto svoji metodu nazvali takto obecně evoluční strategie. Postupem času se však ukázalo, že tento způsob řeší jen určitý typ úloh, zejména ve stavebním a strojním inženýrství. Genetické algoritmy nejsou tedy podřazené evolučním strategiím, ale naopak je svojí popularitou zastiňují.
Evoluční strategie, stejně jako evoluční programování a genetické algoritmy, jsou vhodné především pro optimalizaci funkcí s mnoha maximy a minimy, kde nejsme schopni určit analytické řešení a klasické gradientové techniky selhávají.
1) výběr potomků
Evoluční strategie – u původní implementace lepší potomek jednoduše vytěsní horšího rodiče, který je odstraněn z populace. Pokud potomek není lepší než rodič, pak rodič zůstává v populaci. Pozdější algoritmy generují například z 10 rodičů 100 potomků, potom seřadí rodiče i potomky podle síly (fitness) a vyberou deset nejlepších do další generace. Je možná i taková strategie “vymření” rodičů, kdy se nejlepší jedinci vybírají pouze z potomků.
Evoluční programování – i horší potomci mají ještě šanci, pokud jsou vybráni do slabší skupiny. Skupinky jsou náhodně vybrány z nových (tj. mutovaných) jedinců i z rodičů. Ve skupinkách pak dochází k “turnaji”, potomci jsou seřazeni podle síly a ti nejlepší jsou vybráni do další populace. Počet jedinců v populaci nemusí být konstantní a jedinec může produkovat i více potomků.
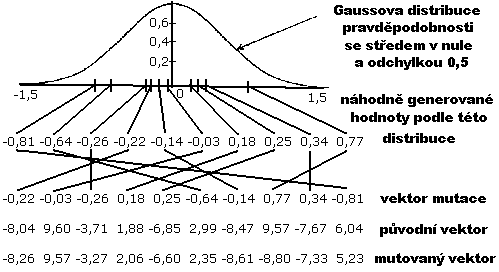
Obr.3: Zobrazení Gaussova normálního rozdělení (se střední směrodatnou odchylkou rovnou 0.5) a deseti náhodně vygenerovaných hodnot odpovídajících tomuto rozdělení. Tyto hodnoty tvoří po patřičném promíchání vektor mutace. Odpovídající hodnoty tohoto vektoru jsou přičteny k vektoru “rodiče” a spoluvytvářejí tak vektor “potomka”, nepatrně odlišného od rodiče.
2) křížení
Evoluční strategie napodobuje vývoj jedinců v druhu, a proto i jejich křížení. Vzhledem k tomu, že jedinci představují zakódované řešení problému, tj. směs reálných čísel, celých čísel aj. parametrů, křížení je specificky definováno pro každý typ problému. Předpokládejme, že máme vybrány dva jedince charakterizované dvěma vektory reálných čísel. Diskrétní křížení vytváří nového jedince, jehož vektor je tvořen hodnotami vzatými buď z jednoho, nebo z druhého vektoru. Tento výběr je náhodný.
Křížení “průměrem” vytváří jedince, jehož jednotlivé hodnoty vektoru jsou vždy průměrem odpovídajících složek vektorů rodičovských jedinců.
Evoluční programování typicky nepoužívá křížení vůbec; napodobuje totiž vývoj
druhů, které mezi sebou soutěží, a mezidruhové křížení většinou nenastává.
Pozn.: Z pohledu genetických algoritmů má evoluční programování výhodu v
pseudonáhodném výběru jedinců, čímž může lehčeji překonat bariéry falešného
lokálního minima. Evoluční strategie má zase výhodu v existenci křížení, kdy
sdílení informace pomůže rychleji dospět k optimu.

Obr.4: Dva z mnoha druhů křížení používaných evoluční strategií.
3) mutace
Mutace je prováděna u každého potomka (nejen u několika málo náhodně vybraných potomků, jako je tomu u genetických algoritmů). Tato mutace spočívá v přičtení náhodného čísla s Gaussovým rozdělením k reálné hodnotě proměnné.
Uvědomíme-li si, že účelem mutace je vlastně drobná odchylka u jedince, vzniklá přičtením náhodného malého čísla blízkého nule k původní hodnotě, dosáhneme odchylky jistěji, něž překlopením bitu u proměnné. (Překlopením bitu na začátku kódu proměnné, jak se může stát u genetických algoritmů, bychom mohli získat mnohonásobnou reálnou hodnotu v porovnání s původní hodnotou. Střední Gaussova odchylka nám sice může dát velké číslo, ale s mnohem menší pravděpodobností.)

Při postupném žíhání nejprve zahřejeme těleso na vysokou teplotu. Tím se jeho atomům umožní překonávat lokální energetické hladiny a tak se dostat do rovnovážných poloh. Postupné snižování teploty má za následek, že se rovnovážné polohy atomů fixují, takže při konečné teplotě žíhání (podstatně nižší než byla počáteční) jsou všechny atomy v rovnovážných polohách a těleso neobsahuje žádné vnitřní defekty ani pnutí.
Počátkem 80. let dostali Kirkpatrick, Gelatt, Vecchi a Černý nápad, že problém hledání globálního minima funkce může být realizovatelný podobným způsobem jako žíhání tuhého tělesa, a nazvali ho metodou simulovaného žíhání.
Uvažujme hypotetický systém popsaný n-rozměrným stavem x = (x1,x2 ,...,xn), kde xi patří do nějakého intervalu. Stavy tohoto systému jsou ohodnoceny funkcí f , která přiřadí každému hodnotu y = f(x) . Naší úlohou je najít takový stav xmin, ve kterém nabývá funkce f globálního minima. Nechť x je přípustný stav systému, ten přejde do nového stavu x´, formálně x´=Opert(x), kde Opert je “operátor” poruchy - perturbace. Otázka, zda bude nový stav akceptován do dalšího procesu, se řeší tzv. Metropolisovým kritériem, resp. Metropolisovým algoritmem, který určuje pravděpodobnost nahrazení starého stavu novým. Celý tento vztah lze zapsat:
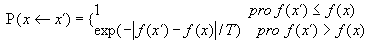 ,
,
kde T je parametr interpretovaný jako "teplota".
Obr.5
V případě, že nový stav x´ má menší nebo stejnou funkční hodnotu jako
původní stav x, potom provedeme záměnu stavu x stavem x´.
V opačném případě je nový stav x´ akceptován s pravděpodobností
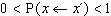 . Nechť random je náhodné číslo
z intervalu (0,1); potom nový stav je akceptován, pokud random
. Nechť random je náhodné číslo
z intervalu (0,1); potom nový stav je akceptován, pokud random
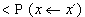 , jinak se proces opakuje s původním
stavem x.
, jinak se proces opakuje s původním
stavem x.
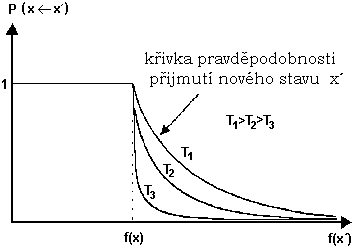
Hodnota parametru T podstatně ovlivňuje hodnotu pravděpodobnosti
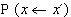 pro případ
pro případ
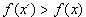 .Pro velké hodnoty T je tato
pravděpodobnost blízká jedné (tj. přijmou se téměř všechny nové stavy), ale
blíží-li se T k nule, potom pravděpodobnost přijmutí je velmi nízká, téměř nulová.
.Pro velké hodnoty T je tato
pravděpodobnost blízká jedné (tj. přijmou se téměř všechny nové stavy), ale
blíží-li se T k nule, potom pravděpodobnost přijmutí je velmi nízká, téměř nulová.
Při vhodném nastavení počáteční “teploty” Tmax (větší hodnota) metoda simulovaného žíhání prohledává nejprve prostor řešení D silně stochasticky, přijímá i stavy s horším ohodnocením než má současné řešení. Tato vlastnost simulovaného žíhání je velmi důležitým rysem této metody, protože poskytuje možnost snadno se dostat z lokálního extrému a prohledat i jiné oblasti v prostoru řešení. Tahle možnost se pak postupně snižuje úměrně se zmenšováním hodnoty T. Pro malé T připustí Metropolisovo kritérium akceptování už jen lepšího řešení než je současné.
Metoda simulovaného žíhání byla testována už v době svého vzniku na známém problému obchodního cestujícího, kdy hledáme nejkratší uzavřenou cestu mezi N místy. Tento problém patří mezi NP-úplné problémy; čas nalezení řešení roste při zvětšování dimenze přinejlepším exponenciálně. Simulované žíhání je schopno nalézt optimální (u složitějších úloh většinou však jen suboptimální) řešení i v případě takovéto úlohy (viz obr.6).
Ukazuje se, že simulované žíhání poskytuje velmi efektivní algoritmus k řešení kombinatoriálních úloh, které jsou NP-úplné, přičemž získaná řešení jsou buď totožná nebo velmi blízká optimálním řešením.
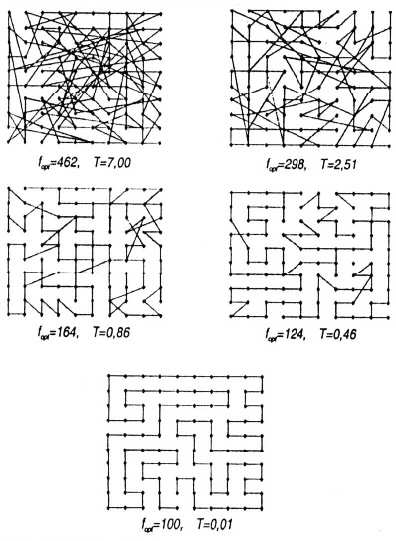
Obr.6


Jedním z mnoha optimalizačních algoritmů a heuristik je metoda zakázaného prohledávání, na které zajímavé, že byla navržena teprve před několika lety, a přitom je tak jednoduchá a efektivní, že se okamžitě zařadila mezi nejlepší algoritmy používané pro optimalizaci v operačním výzkumu. Navrhl ji koncem osmdesátých let profesor Fred Glover z University of Colorado a sám ji také nazval tabu search.
Tato metoda dokáže najít přijatelné optimum za velmi krátký čas, pokud je přijatelných minim ve sledované funkci více. Při prohledávání funkcí s mnoha minimy, ale jen málo přijatelnými minimy, má tato metoda trochu problémy. Její základní myšlenka totiž spočívá v logickém vylepšení algoritmu “slepého horolezce” (hill climbing algorithm). Jedná se tedy o variantu gradientní metody “bez gradientu”, protože se směr nejprudšího spádu určí prohledáváním okolí. Tento algoritmus proto trpí základní nectností gradientových metod, tj. často skončí v lokálním extrému a nedosáhne globálního minima. Vychází se zde z náhodně navrženého řešení. Pro aktuální navržené řešení se generuje konečným souborem transformací určité okolí a vybere se z tohoto okolí nejlepší minimum. Získané lokální řešení se použije jako “střed” nového okolí, ve kterém se lokální minimalizace opakuje. Tento proces projde předepsaným počtem opakování. V průběhu celé historie algoritmu se zaznamenává nejlepší řešení, které slouží jako výsledné minimum. Aby nedošlo k zacyklení, spustí se algoritmus několikrát s náhodně vygenerovanými počátečními stavy a poté se vybere nejlepší výsledek.
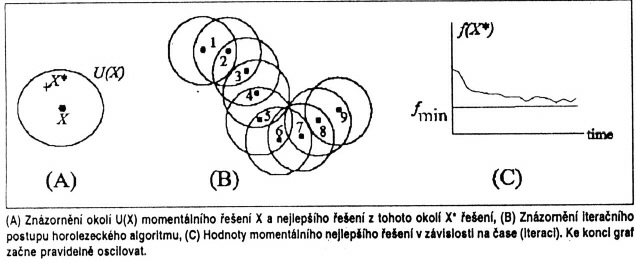
Do tohoto algoritmu je zavedena tzv. krátkodobá paměť, která si pro určitý krátký interval předcházející historie algoritmu pamatuje inverzní transformace k lokálně optimálním transformacím řešení, použitým k získání nových “středů” pro jednotlivé iterace. Tyto inverzní transformace jsou zakázány (tabu) při tvorbě nového okolí pro dané aktuální řešení. Tímto jednoduchým způsobem je možné podstatně omezit výskyt zacyklení při pádu do lokálního minima.
Krátkodobá paměť je realizována "zakázaným seznamem" T (tabu list) s obsluhou typu LIFO (zásobník), který je vytvořen a obnovován při vykonávání algoritmu. Jestliže tedy nějaká transformace patří do zakázaného seznamu, pak nemůže být použita pro lokální minimalizaci. Numerické zkušenosti s metodou zakázaného prohledávání ukazují, že velikost (délka) zakázaného seznamu je velmi důležitým parametrem ovlivňujícím schopnost vymanit se z lokálního extrému. Příliš malá délka nemusí zabránit zacyklení a příliš velká může způsobit přeskočení nadějných lokálních minim.

Mezi problémy úspěšně řešitelné metodou zakázaného prohledávání patří problém obchodního cestujícího, problémy rozvrhu práce pro stroje v továrnách, návrh komunikačních sítí, strategické rozmístění skladů, logistické problémy v ekonomice a mnoho dalších.
Technika zakázaného prohledávání může být použita jak v klasickém spojení s horolezeckým algoritmem, tak i v kombinaci s jinými algoritmy, např. se simulovaným žíháním nebo genetickými algoritmy. U těchto metod však nebývá příliš efektivní; tyto metody neprohledávají celé okolí aktuálního řešení a pravděpodobnost zapůsobení zakázaného seznamu je tedy dost malá.

Umělý život (Artificial Life) je rychle se rozvíjející oblast vědeckého výzkumu spojující biologii a informatiku. Snaží se včlenit procesy podobné životu do počítačových programů. Hlavním rysem tohoto oboru je formulování základních pravidel chování jednotlivých ”organismů” a jejich replikace, přičemž cílem je dosáhnout vývoje organismů a jejich vzájemných vztahů.
Ve vztahu ke klasické umělé inteligenci je umělý život orientován opačným směrem. Zatímco se umělá inteligence snaží o přístup shora dolů, tj. program musí být v první řadě inteligentní a je na programátorovi, jak toho dosáhnout, umělý život se snaží vytvořit jen základní pravidla, která budou tak vhodně zvolena, že se složitější chování vytvoří po čase samo.
Umělá inteligence a umělý život mají k sobě nejblíže v typu programů nazvaných autonomní agent. To je program, který obahuje nějaký druh vnímání okolního prostředí a návazně ovlivňuje vlastní stav, stav okolních agentů nebo prostředí samotné. V Americe už se autonomní agenti využívají na praktické úlohy: řízení letového provozu nebo provozu továrny, kdy každý stroj má svého agenta starajícího se o dodávky energie, surovin a odvoz hotových výrobků. Toto využití je však stále ještě velmi nákladné. Za autonomního agenta může být považován i počítačový virus, ale v praxi se od agenta liší svojí jednoduchostí a tím, že má jen jeden hlavní cíl – rozšiřovat se.
Mnoho aplikcí umělého života vybavuje své organismy umělou neuronovou sítí,
která slouží jako umělý mozek, schopný natrénovat se z příkladů s předem zadaným
výsledkem. Typicky je neuronová síť tvořena vstupními neurony, napojenými na
informace získávané z okolního prostředí, skrytými vrstvami neuronů, provádějícími
většinu výpočtů, a výstupními neurony, které určují další akci organismu – agenta.
Literatura :
I když jsou jak genetické algoritmy, tak i evoluční programování a evoluční strategie
natolik podobné, že je téměř nemá smysl od sebe striktně rozlišovat, vzhledem k
historickému vývoji si různé vědecké komunity, fandící jednotlivým metodám, udržují
od sebe nesmyslně velký odstup.


Internet