|
Gramatiky a jazyk
Gramatika jazyka představuje soubor pravidel, pomocí nichž lze z prvků abecedy (množina všech primitiv = písmena)
vytvářet slova (popisy předmětů) náležející do daného jazyka. Pomocí gramatiky lze charakterizovat i nekonečné
jazyky.
K popisu formálního jazyka se používá gramatika, což je matematický model generátoru slov tohoto jazyka.
Gramatika je čtveřice pravidel G = (Vn, Vt, P, S), kde
Vn, Vt jsou disjunktní, prvky Vn se nazývají
neterminální symboly, prvky Vt terminální
symboly, S je tzv. axiom gramatiky neboli počáteční symbol a P
je konečná neprázdná podmnožina množiny
V* x V*, jejíž prvky se nazývají substituční pravidla V* = Vn
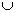 Vt.
Vt.
Množina všech slov, která mohou být generována gramatikou G, se nazývá jazyk L(G). Gramatiky, které generují
tentýž jazyk, se nazývají ekvivalentní.
Podle tvaru substitučních pravidel se gramatiky dělí na 4 typy:
-
gramatiky typu 0 - obecné gramatiky, nemají žádná omezení na tvar substitučních pravidel,
-
gramatiky typu 1 - kontextové gramatiky, jejichž substituční pravidla mají tvar
W1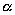 W2 --> W1UW2 a mohou
obsahovat pravidlo S--> W2 --> W1UW2 a mohou
obsahovat pravidlo S-->
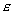 (
je prázdné slovo), W1,W2,U
(
je prázdné slovo), W1,W2,U 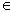 V*,
U V*,
U
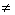 , Vn
(tz. neterminální symbol lze nahradit
slovem U v kontextu slov W1 a W2).
, Vn
(tz. neterminální symbol lze nahradit
slovem U v kontextu slov W1 a W2).
-
jazyky typu 2 - bezkontextové gramatiky, jejichž substituční pravidla mají tvar
-->U, kde U V*,
U
,
Vn, a mohou obsahovat pravidlo S-->
(neterminální symbol lze nahradit slovem U nezávisle na kontextu, ve
kterém je použit).
-
jazyky typu 3 - regulární gramatiky, jejichž substituční pravidla mají tvar
-->x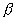 nebo
--> x, kde ,
Vn, xVt, a mohou také obsahovat pravidlo S-->
. nebo
--> x, kde ,
Vn, xVt, a mohou také obsahovat pravidlo S-->
.
Gramatiky, o nichž jsme hovořily se nazývají nedeterministické. Odpověď na to, zda dané slovo je generováno danou
gramatikou či ne, dává postup zvaný syntaktická analýza.
Je-li gramatika regulární (typu 3), je syntaktická analýza jednoduchá. Gramatika se nahradí ekvivalentních konečným
nedeterministickým automatem a snadno se zjistí, zda slovo x je automatem přijato či ne.
V případě bezkontextových gramatik G (typu 2) je to pracnější. Existuje způsob realizace zásobníkovým automatem a
to shora dolů (od kořene stromu, od počátečního symbolu gramatiky) nebo
zdola nahoru.
Inference gramatik
Aby bylo možné modelovat jazyk určité třídy vzorů co nejsprávněji, je snaha vytvořit
gramatiku a její pravidlo přímo z
množiny vzorových obrazů. Tento problém určení gramatiky na základě vzorových vět se nazývá inference gramatik.
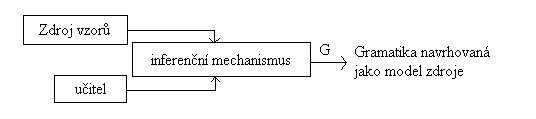
Zdroj vzorů generuje řetězy složené z konečného počtu terminálních symbolů. Všechna slova, která mohou být
generována zdrojem, jsou obsažena v množině L(G) - v jazyce generovaném gramatikou G, zatímco slova, která
nemohou být zdrojem generována, tvoří doplněk množiny LC(G). Tato informace je vstupem algoritmu inference, jeho
úkolem je nalézt neznámou gramatiku G. Slova z L(G) lze snadno získat sledováním výstupu zdroje, avšak prvky
LC(G) musí určit vnější učitel, který má k dispozici další informaci o vlastnostech gramatiky G.
Počet vzorových slov je konečný a to nestačí k jednoznačné definici potenciálně
nekonečného jazyka L(G). Jakékoli
konečné množině vzorů může být přiřazen nekonečný počet jazyků. Proto zpětně nemůžeme nikdy očekávat
jednoznačnou identifikaci gramatiky, která generovala vzorové řetězy. Od inferenčního algoritmu očekáváme, že
vytvoří gramatiku, která popíše vzorovou množinu a navíc další slova, která mají v určitém smyslu stejnou strukturu
jako vzorová.
Obecně lze metody inference rozdělit do dvou kategorií:
1. ENUMERACE - výběr takové gramatiky z konečné množiny M gramatik, která generuje celou vzorovou množinu
nebo alespoň její největší část.
2. INDUKCE - na základě tvaru slov z trénovací množiny se usuzuje, jak by měla vypadat slova podobná slovům z
trénovací množiny, a podle toho se stanovují substituční pravidla.
Obecná metoda inference gramatik na základě předloženého seznamu slov jazyka dosud neexistuje, vytvořené metody
lze použít pro regulární a bezkontextovou gramatiku a pro některé další speciální případy.Gramatiky jsou konstruovány
na základě heuristik, intuice, zkušenosti a samozřejmě apriorních informacích o úloze.
Podrobnější informace lze nalézt v [7,
20].
|