|
Počítačové zpracování přirozeného jazyka Úvod Počítačové zpracování přirozeného jazyka představuje velkou výzvu a perspektivní zaměření výzkumu a vývoje v celé řadě praktických činností člověka s informacemi. Může jít například o:
Gramatika Přirozený jazyk jako systém sloužící ke komunikaci mezi lidmi, se obvykle popisuje dvěma základními "datovými (informačními)" strukturami: slovníkem (lexikem) a gramatickou (mluvnicí). Slovníkem rozumějme množinu slov, která lze v daném jazyce použít, nebo která v něm mají nějaký význam (lexikální sémantika). Zatímco v teorii formálních jazyků [7, 20] je "gramatika" pojímána jako uniformní systém pravidel popisujících způsoby, jakými se z "abecedy" sestavují "slova", v lingvistice (jazykovědě) se obvykle rozlišuje několik úrovní gramatiky:
Otázku náročnosti jednotlivých úloh počítačového zpracování přirozeného jazyka bychom tedy mohli formulovat takto: Jakou míru "sémantické hloubky" - čili jakou míru komplexnosti lexikálního a gramatického rozboru - musí systém zahrnovat? Stačí např. rozlišovat jednotlivá slova, nebo slova a jejich tvary, nebo je nutno rozlišovat i jejich syntaktické funkce, případně něco ještě "hlubšího"? Základní výzkumně-aplikační disciplína, která se této problematice věnuje, se nazývá aplikovaná lingvistika, komutační ligvistika nebo počítačová lingvistika. Jako její blízký obor je třeba jmenovat algebraickou lingvistiku, neboli formální lingvistiku - vědu zkoumající přirozený jazyk jako matematický model. Je třeba si uvědomit, že přirozený jazyk je velmi složitý systém a jeho používání člověkem asi nikdy nebude exaktně popsáno, aby mohlo být plně napodobeno počítačem. v následujících oblastech řekneme známe reálné možnosti a meze automatizace několika základních úloh zpracování přirozeného jazyka - indexování textů, vytvoření tezaurů, referování (tvorby abstraktů), překladu textů, učení (extrakce elementárních znalostí) z textů, korektury textů. Automatické indexování textů Indexováním nazýváme proces přiřazení selekčních obrazů (výraz nebo množina výrazů určitého selekčního jazyka např. všechna podstatná jména, předem daná podstatná jména, ...) dokumentům nebo dotazům. Následně dochází k zatřídění selekčních obrazů dokumentů do nějaké struktury umožňující vyhledávání požadovaných prvků, resp. porovnávání. Jako klíčový problém automatického indexování textů, který je nutno vyřešit, pak zbývá určení, která slova textu nejlépe charakterizují jeho celkový obsah. Lingvistické problémy automatického indexování lze rozdělit do těchto okruhů:
Automatické indexování pomocí TEZAURU Jedním z těžko odstranitelných problémů automatického indexování textů výrazy vybranými přímo z textu je fakt, že informační požadavek může být vyjádřen i jinými výrazy přirozeného jazyka. V zásadě lze rozlišit přinejmenším tři typy takových situací:
Daný problém představuje "koeficient selekční významnosti". Klasickým nástrojem řešení obou zde uvedených problémů je indexování dokumentů a dotazů tezaurus. Tezaurus Termínem tezaurus se obecně nazývá slovník obsahující:
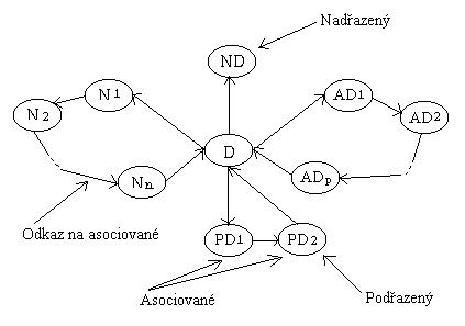
Tezaury nemusí sloužit pouze pro indexování, ale např. jako pomůcka pro autory textů. Tezaury určené pro indexaci jsou zpravidla omezené na terminologii určité užší odborné oblasti. Ústředním pojmem je deskriptor - z každé skupiny synonymních termínů je vybrán jeden reprezentant, který by měl být používán k popisu (deskripci) skutečného nebo požadovaného obsahu textu. Všechna ostatní synonyma jsou nazvány nedeskriptory. Pouze mezi deskriptory se zachycují vztahy (vazby) - nadřazený, podřazený, asociovaný, ekvivalentní (pouze u více jazyků) deskriptor. Počítačový záznam musí vedle odkazů na ekvivalentní nedeskriptory efektivně poskytovat také odkazy na všechny nadřazené, podřazené a asociované deskriptory.
Automatické referování V teorii zpracování přirozeného jazyka je obvykle referát (abstrakt) uváděn jako jeden z možných výstupů intelektuálního procesu nazývaného informační analýza dokumentů. Definice referátu dle ČSN: Referát je zkrácený výklad obsahu dokumentu (nebo jeho části) s hlavními věcnými údaji a závěry, který zdůrazňuje nové poznatky a umožňuje rozhodnout se o účelnosti studia původního dokumentu. Rozdíl mezi úlohami indexování a referování by mohl být formulován velice jednoduše: může-li být cílem indexování extrahovat (resp. formálně odvodit) z textu vhodný počet slov či sousloví, která nejlépe vystihují o čem text je, pak cílem referování může být extrahovat (resp. formálně odvodit (z textu vhodný počet vět, které nejlépe vystihují, co text přináší nového. Rozlišujeme automatické referování založené za tezauru či založené na měření obsahových souvislostí mezi větami. Překlad textů Na celém světe se dnes každodenně překládá asi 150 milionů stran textu. Z toho jen 0,3 % připadá na krásnou literaturu, 35 % tvoří obchodní informace, 21 % průmyslové, 20 % vědecké, 9 % právní, ... Tedy minimálně 85 % informací spadá do "oblasti zájmu". Tyto informace jsou většinou zpracovány počítači (od psaní, šíření, informační analýzu a indexování až po vyhledávání a využívání). Bylo by tedy žádoucí, aby se počítače zapojily do překladu do jiných jazyků. Strojový překlad 1. generace Systémy strojového překladu tzv. 1 generace typicky pracovaly způsobem konečného automatu - vytvářely překlad typu "slovo za slovo". Jednalo se tedy o velmi hrubý překlad a bylo nutnost se nezřídka vracet k originálu při upravování do podoby odpovídající gramatice výstupního jazyka. Strojový překlad 2. generace nazýváme systémy, ve kterých jsou nějakým konzistentním způsobem odděleny pracovní fáze řešící:
Systémy 3. generace můžeme nazývat ty, které uplatňují některé přístupy umělé inteligence. Podrobnější informace můžete nalézt v [6]. |